本文主要介绍我在公司黑盒扫描器演进中对构架的一些实践思考
0x00 说说背景
我目前所在的公司是一家互联网金融公司,目前员工加外包不到5000人,其中技术人员占了大多数,目前子系统超过2000个,但对公网服务不到1000个端口,URL不超过5W,内网服务因为涉及到金融服务,稳定性重要,CGI一类的不允许扫描,大概2W台机器,几W个开放端口
和百度的这篇扫描器实践文章,我服务的对象没有5W多域名,7000W多URL那么大的体量,在全年众测和SRC活动下被白帽子发现的漏洞也没有那么多,自身扫描器发现的漏洞也没有那么多,因此也没有那么复杂的构架,一些需要解决的问题点也不同,也不需要那么健壮,比如热更新、自动恢复等功能就没有了
所以我自研扫描器主要目标也只有扫描器本身的扫描能力提高(漏报误报),和保证运营(比如日扫和资产及时更新)能够完成即可,我一个人写代码,提供给20几个应用安全的同事使用,今后可能会提供给各个业务用户他们自身的上线前渗透测试
这里仅仅说说我在工作中的一些实践思考
0x01 从百度扫描器看构架
我们先看看百度扫描器实现的构架图
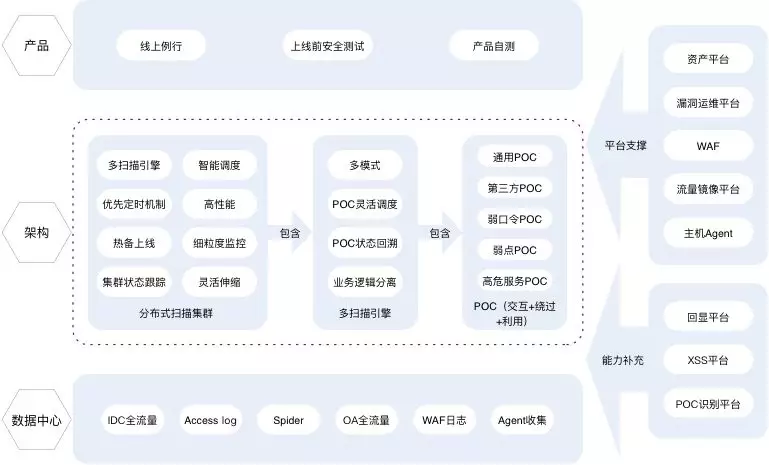
我们把这个图拆解一下,数据中心和平台支撑其实是一个意思,就是资产来源,我们需要考虑的其实是如何获取资产和资产以什么结构保存,也就是资产模块的设计
产品一栏其实是我们扫描的需求,一是线上例行扫描(运营需要),二是上线前安全扫描,三是产品自测,其实我们划归一下从用户和功能上来讲,扫描有两种需要,一是周期性扫描功能(用户为安全部),二是临时扫描功能(用户为安全部和普通业务),所以需要的其实是权限功能和临时、周期扫描功能的设计
然后是构架中的分布式扫描集群、多引擎扫描其实就是扫描任务调度功能
最后是PoC和能力补充,其实我们自己写的规则,一般来讲,PoC分成服务PoC(包含指纹识别和漏洞检测)和CGI PoC(HTTP服务的指纹识别和漏洞检测)
再看后一张图,其实就是保证扫描器稳定运营,也就是扫描器集群状态的监控,也就是为了保证运营需要,百度加了很多功能,我们的体量其实不用,只需要保证扫描任务成功,扫描流程日志收集即可,前者保证基础功能的可正常运行,后者保证部分细节的可单独优化
我们总结一下
- 权限模块
- 资产模块
- 任务调度模块(单发和周期性任务,PoC调度)
- 任务监控模块
- 流程日志收集模块
0x02 构架的演进之路
扫描器不是一蹴而就的,我先讲讲我自研黑盒扫描器的几次重大变更
从无到有
从无到有的过程中,拿一个垃圾扫描器扫着,和拿一个牛逼的扫描器扫着,都能发现不少问题,资产覆盖率更重要
这个过程中,对一个公司来说,扫描器的能力高低是第二位的,对大多数公司来说,能更多的覆盖资产才是第一要务
因此第一要务是完善CMDB,对IP、域名和端口服务等进行完善,因为CMDB不全、不准,所以subdomain和nmap的资产收集扫描都是必要的,这时候nmap慢没关系,写得是脚本随便扫没关系,重要是发现CMDB的一些问题,及时修改CMDB
有了一份还算全的资产,之后就是用PoC拿来扫描
我们上面说了,一般来讲,PoC分成服务PoC(包含指纹识别和漏洞检测)和CGI PoC(HTTP服务的指纹识别和漏洞检测)
初期的时候没有维护规则的能力,肯定是内外网服务PoC拿nesses、nexpose或者openvas这些随便顶上,内网CGI PoC用AWVS、APPScan等随便顶上,能买就买,不能买就盗版
反正从无到有,这时候肯定能发现不少问题,先运营覆盖了,肯定也要花一大段时间
这个时候我们积累实际能力是服务资产模块的设计,包括它的存储、获取和发掘的能力
CGI覆盖
基本的服务资产有了,虽然HTTP服务使用了AWVS等,但是CGI还是无法保证的
这个时候使用的是渗透和CGI结合的方式,用到的工具是burp suite
我们需要对业务周期性进行渗透,渗透人员工作的时候都是使用burp suite的,burp的被动抓包能力可以比较全地覆盖CGI,利用这一特性,我们通过对burp写插件,将被动扫描过程中的CGI收集到我们的资产中
burp甚至帮我们做了去重的工作,调用burp的scanner的时候burp会去重,我们对burp上报CGI的插件写在调用scanner的时候上报,同时解决CGI收集和去重
这时候还有两个问题因为和业务相关性太大无法解决
- 收集的CGI的登录态会失效以及一些金融业务中的时间戳、流水号和CSRF Token等会影响扫描效果
- 一些诸如开户、交易的接口有成功率统计,一旦渗透或者扫描过程中的PoC导致成功率太低,会令业务抓狂
这时候想到的办法仍然是burp插件去覆盖和业务相关性太大的这两个问题,也意味着我们的扫描也是要通过burp,幸好外网业务不到1000,还有因为负载均衡而相同的,这时候可以让渗透人员为自己的业务编写获取登录态、CSRF Token的burp插件,保证扫描准确,同时渗透人员通过插件上报CGI的时候去掉哪些会导致业务抓狂的敏感功能的接口
这时候CGI扫描的覆盖用burp也差不多完成了
这个时候我们积累的实际能力是CGI资产模块的设计,和业务强相关的一些登录态、CSRF Token规则
PoC能力加强
有了以上两步,其实我们基本覆盖了资产的扫描,随之问题也出现了,最头疼的无非就是漏报误报,然后是新CVE没有应急响应
比如点击劫持,AWVS和burp基本没有X-Frame-Options的头部都会报,burp会将所有json返回的保留payload都标记为XSS,然后一些sql的漏报没有sqlmap准确等
所以我们需要加强自身的扫描能力
这个时候所有资产都是有了,扫描只需要针对漏洞类型增加PoC,不管是CGI还是普通服务,还是应急响应,功能增加回显平台等也是PoC中的内容,而之前CGI的登录态和CSRF Token的规则就需要重写了,也就是PoC中需要prehandle处理
虽然我们自己写了PoC,但是多为脚本拉取资产跑,此时我们运营的是我们自己写的PoC,但是同时原来的nessus、burp、AWVS也不要停,定期用来做对比,有时候它们发现的一些问题可以帮助我们完善规则
健壮性加强(权限、任务调用、监控与日志)
有了上面的PoC,我们就有了扫描器最重要的能力,之后要做的就是完善能力,提高健壮性
基于以后会需要给业务通过用来产品自测和SDL的上先前自测,需要提供权限管理功能,添加RBAC访问控制模型
PoC不能用脚本再跑,不方便维护,添加任务调度的功能
对扫描任务的运营,需要添加监控
对于漏洞误报的纠察需要添加扫描流程的日志收集以供分析
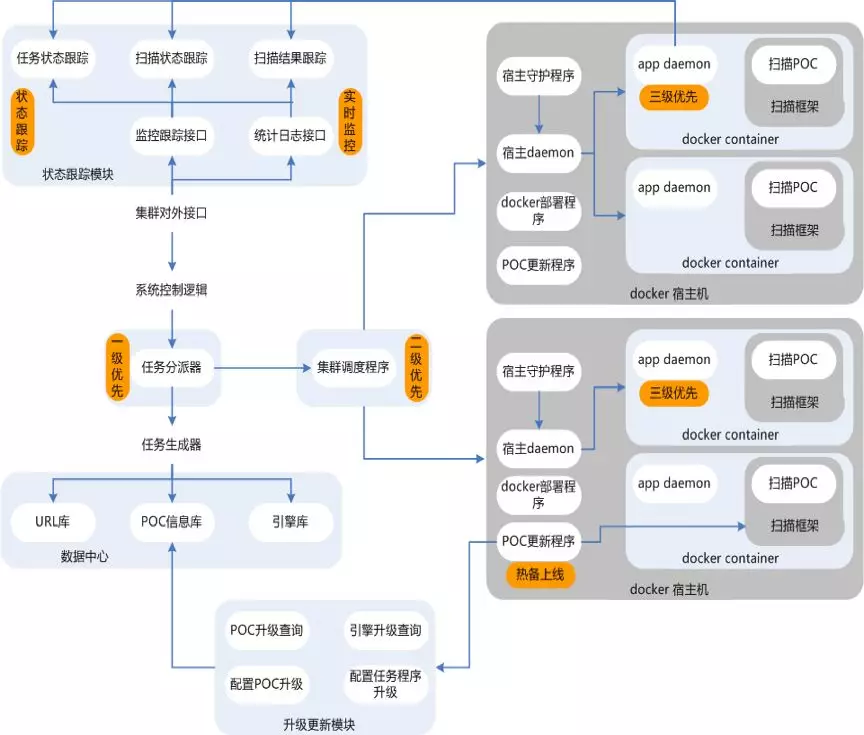
0x03 成型的扫描器
构架设计图
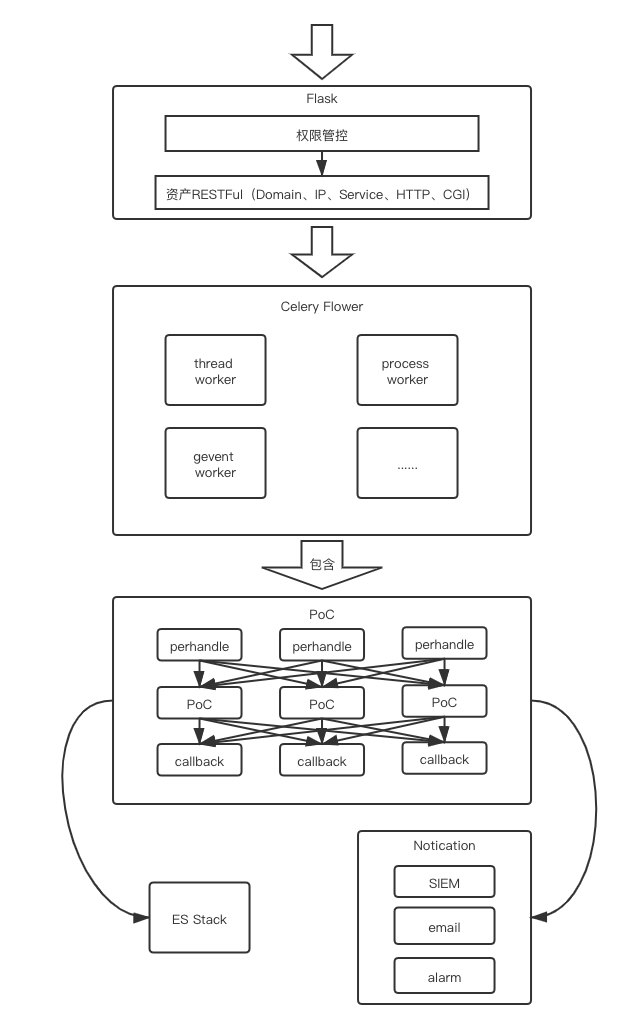
RBAC模型和资产RESTFul
首先是入口的web程序,Python Flask开发,MySQL作为数据库
- 一个是RBAC垂直权限和接口水平权限的区分
- 一个是提供资产RESTFul风格的增删改查接口,用来推和拉资产,保证扫描的资产准确
垂直权限的RBAC的设计可以看我之前的文章Web访问控制——授权(RBAC模型)
水平权限就按特殊接口写逻辑
资产主要分成
- Domain:域名
- Host:IP
- Service:服务(IP+端口)
- HTTP:web应用
- CGI:web应用对应的CGI
- 其他(如果有一些特殊需要)
这里以MySQL作为数据库,主要是因为公司开发使用MySQL,有不懂可以寻求他们帮助,他们更有经验
RESTFul风格API主要用来
- 让队友调用资产用来做个人测试
- 与CMDB互通有无
- 其他安全团队的资产补充和例行任务调用
任务调度模块(单发和周期性任务,PoC调度)
任务调度是直接用celery框架和celery-flower完成的,rabbitmq作为broken,redis作为backend
使用celery有几个好处
- celery本身就是异步任务调度框架,对单发和周期性任务本身就有极好支持
- celery的worker调度非常完善,对网络编程非常友好,支持多进程、多线程、gevent和eventloop的协程,无需对PoC适配
- 本身调用灵活,对与PoC执行前后的
prehandle和callback都十分容易实现 - celery flower对任务控制有完善界面支持,对worker性能观测也非常友好
- 可以实现百度扫描器文章中说的
单目标+单PoC
举例子
如果我的PoC多进程执行快,我只要多启动几个celery worker就可以
如果我的PoC多线程执行快,我只需要对celery worker的启动项添加-c n(n为thread数量)的参数就可以
如果我的PoC协程执行快,我只需要对celery worker的启动项添加-P gevent的参数就可以
所有的网络编程变化只需要调整celery的worker参数,而不用对PoC和控制逻辑适配,而整个任务的调度都交给celery,它会处理很好
实际使用中,我们在机器上用supervisor开启几个不同worker组,对扫描任务根据不同对PoC在调用对时候分配到不同组中
下面这张图是我一次调试PoC,提高性能的过程
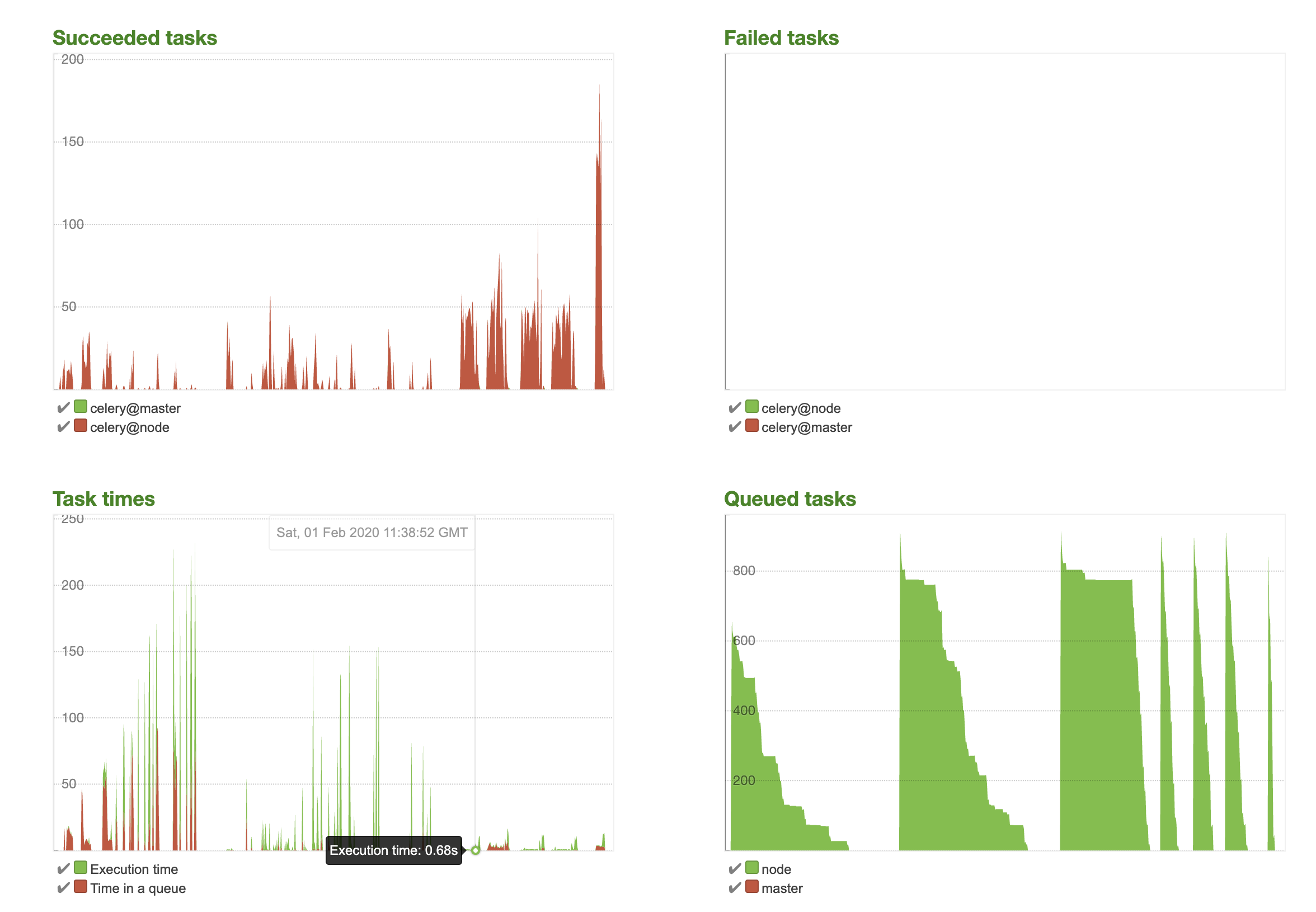
可以看到,celery flower完整记录下了整个调试的变化过程,非常直观,从最开始1000个请求10分钟到后面20秒完成,真的非常直观、方便
任务监控与日志收集
任务监控其实就是对任务callback是否有校验任务结果,也就是我们的任务执行中需要有callback的部分,用来发邮件,通知SIEM,发出告警,具体,可以根据各个系统的实现灵活定制
日志收集就是记录任务的单目标、单PoC和执行结果,对错误或者请求响应收集,用来做误报漏报的分析,我使用ES Stack,有两个好处,一个是Dashboard方面可视化统计,一个是所有PoC同添加在es中,遇到问题了过滤查询都非常方便
比如如下显示
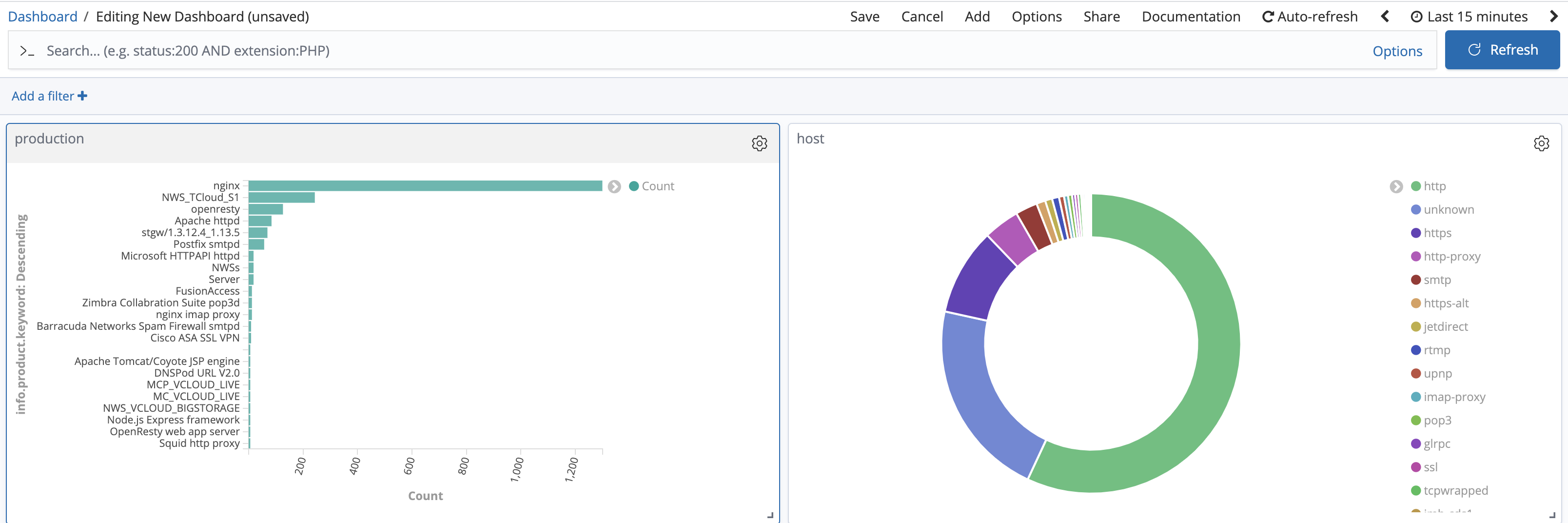
我公司很多东西都用Echarts画图,实际上安全需要的图也不是很多,直接用kibana很方便
0x04 效果检测
这样黑盒扫描器用的爽不爽,就是效果,在我的工作中,主要的一些操作不需要改代码或者该代码了去部署不需要费心思就是爽,就是以下的一些操作用的爽
- 资产更新,CMDB又漏什么了,可以让他们加,自己更新到我们资产中,不用我动手,让他自己调接口,并且改的地方都不需要我再改表结构
- 应急新增了一个PoC,插件写好传上去就可以,运行结果和效果都直接访问Web可以看到,写PoC不需要考虑关心输入输出,可以解耦
- 有漏报误报了可以马上到ES查看所有记录,分析起来方便
- 运营需要添加新的通知,改改callback不需要考虑其他,这里解耦
- 网络编程改写方便,PoC进程、线程、协程变化不需要重新适配、重新部署
- PoC写完容易让人看懂,方便迁移或者改写到别人自己喜欢到框架里
反正用的爽就是好的

