0x00 概述
- 本文先简述了访问控制模型
- 主要讲RBAC模型的设计与实现方案、可用技术,一般来说,RBAC模型可以完全解决垂直权限的访问控制问题,再多加一些限制的情况下可以一定程度上解决水平权限问题
- 根据系统复杂性可以自行设计和选择一些方案,简便或者重型的,保持RBAC模型构架完整即可
0x01 访问控制模型
我们谈到权限的时候,很容易在用户发起请求时对接口做一层权限验证,或者对数据库读写权限限制,往往是如下的硬编码
if not user in ['xxx', 'yyy', 'zzz']:
return "403"
这是一个快速有效的改法,在很多急着上线的时候很有用,但是硬编码的方式,在Web系统这个产品不断迭代,处理逻辑不断变化的场景下,今天这段处理逻辑前加上硬编码,明天那个处理逻辑前加,后天再删掉,这样总是不怎么好,也容易出现疏漏,所以我们有必要引入模型来规范化权限控制
访问控制模型是规定主体如何访问客体的一种构架,它使用访问控制技术和安全机制来实现模型的规则和目标,之所以叫做访问控制模型,带上模型这么高端的名字,是因为在论文里面,它们都是这么表示的

这样的模型内置在不同操作系统的内核或者支持性的应用程序中,不同访问控制模型用不同的相关支持技术适用在不同场合
我们把这样的模型引入Web系统中,用中间件、白名单的方式统一管理,方便修改,更具有较好的扩展性
先来概述一下常见的模型概念
自主访问控制和强制访问控制
一般的访问控制模型可以分为两类:自主访问控制和强制访问控制
自主访问控制(Discretionary Access Control,DAC)
如果客体的拥有者主体可以通过设置访问控制属性来允许其他主体对这个客体进行访问,这样的访问控制就是自主访问控制
最典型的例子就是Linux的ACL表,文件拥有者可以控制用户自己、用户组和其他人对文件的读写执行权限,而umask又为每个文件赋予默认权限,不必每个文件配置,方便具有灵活性
在自主访问控制中,用户拥有非常强大的自由裁量权,是许多客体拥有者,一旦用户权限过多,恶意软件以这个用户身份执行,这个软件的代码就拥有用户的所有权限和许可,且可以执行这个用户在系统上可执行的任何活动
强制访问控制(Mandatory Access Control) 只有系统才能控制对客体的访问,而主体不能改变这种控制,那么这样的访问控制称为强制访问控制
这种模型大大减少了主体的权利、许可和可用功能,仅供用户从事非常特定且具体的活动
这种模型更为结构化、更为严密,并且基于安全标签系统,主体和客体都有相应标签,系统会根据主体的安全许可、客体的分类以及系统的安全策略来做出决策
典型的例子是SE Linux,大学的时候用SE Linux配置RBAC,用前人的策略配置文件,大概几万条,配好了以后普通用户身份连系统都登录不进去,还得在几万条策略里定位,所以强制访问控制一定要明确系统的功能,并很少变更才好用
然后我们比比这两种访问的优缺点
- 自主访问控制:灵活,权限变多、功能变多、变复杂会不容易控制
- 强制访问控制:不灵活、实现复杂,更严密和结构化
RBAC
一图流解释RBAC模型,出自RBAC模型论文
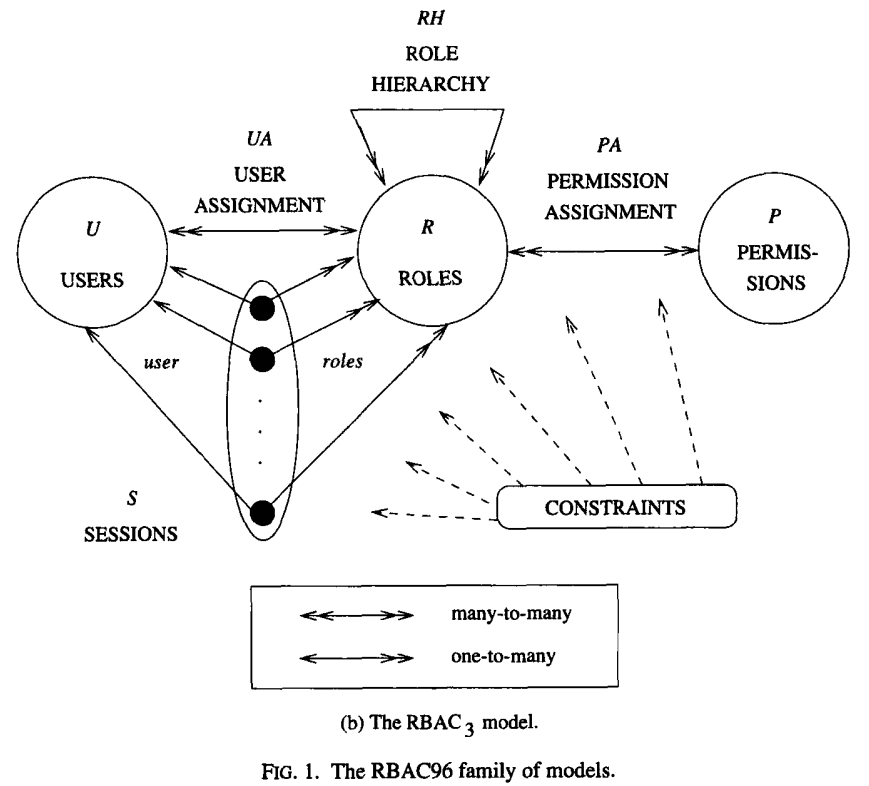
RBAC模型是雇员流动性(入职离职变更岗位)高的公司最适合的访问控制模型,用户——角色——权限对应层级模型也很方便组织机构结构化的特点
上面说一般的访问控制模型都可以分为强制访问控制和自主访问控制,但是RBAC有争议,《CISSP认证考试指南》把它独立出来,认为是一种独立的模型
个人觉得RBAC是系统(或者管理员)规定主体操作,应该属于强制访问控制,只是根据社会组织结构加了一层中间层角色,变得更加灵活。而在一些功能上(比如选择文章是否公开)可以赋予一些主体对所拥有客体的控制访问的权限,这时就是强制访问控制和自主访问控制结合了,这也看系统的具体设计、功能需要和实现方式
Web系统更属于需要强制访问控制的系统,因为类似公开个人信息和文章这样的操作其实很少,更多是管理员和系统决定权限,而Web业务也会越来越复杂,主体和客体都不断增加,如果客体按ACL一类的方式控制,很可能会授权一些非必要访问权限,无形中扩大用户权限,导致违反最小权限原则
那么我们考虑Web系统要用强制访问控制,又不想配置实现过于复杂,而正好一般公司内部使用系统带有公司层级结构,对外产品也有VIP等级之分,这时,RBAC模型的角色控制更适用和更方便
其他访问控制模型
再讲两种大学里常讲的访问控制模型
Bell-LaPadula模型
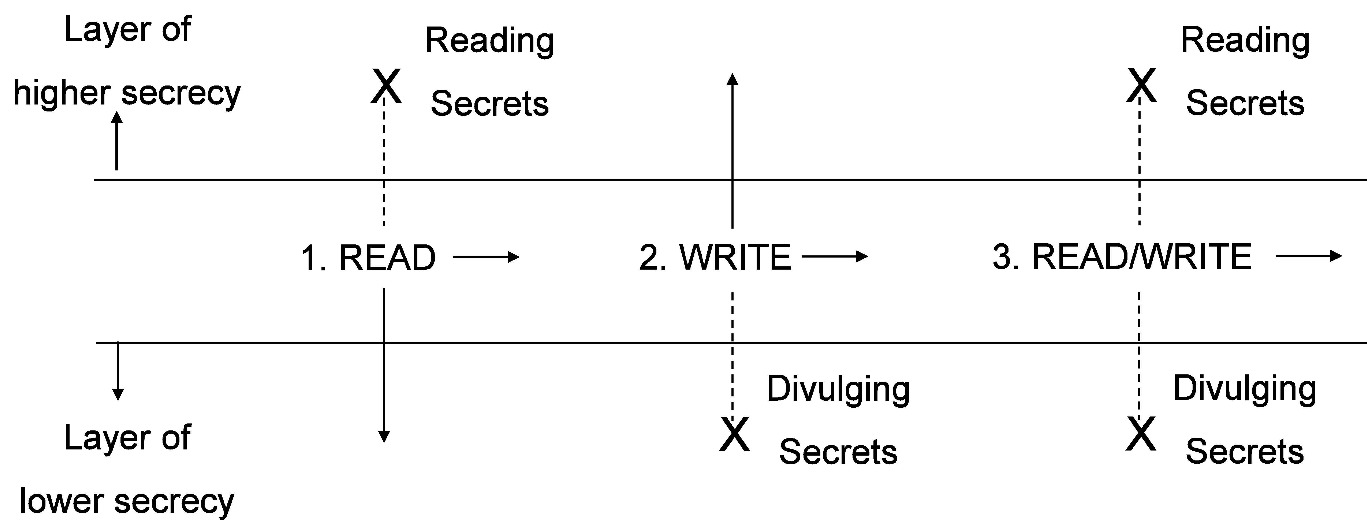
BLP模型解决数据机密性,按上图主要三种规则
- 低安全级别不能读高安全级别信息(防止低安全级别主动获取高安全级别机密,不向上读)
- 高安全级别不能写入低安全级别信息(防止高安全级别主动泄露机密给低安全级别,不向下写)
- 同一主体只能在同一安全级别上执行读写
Biba模式
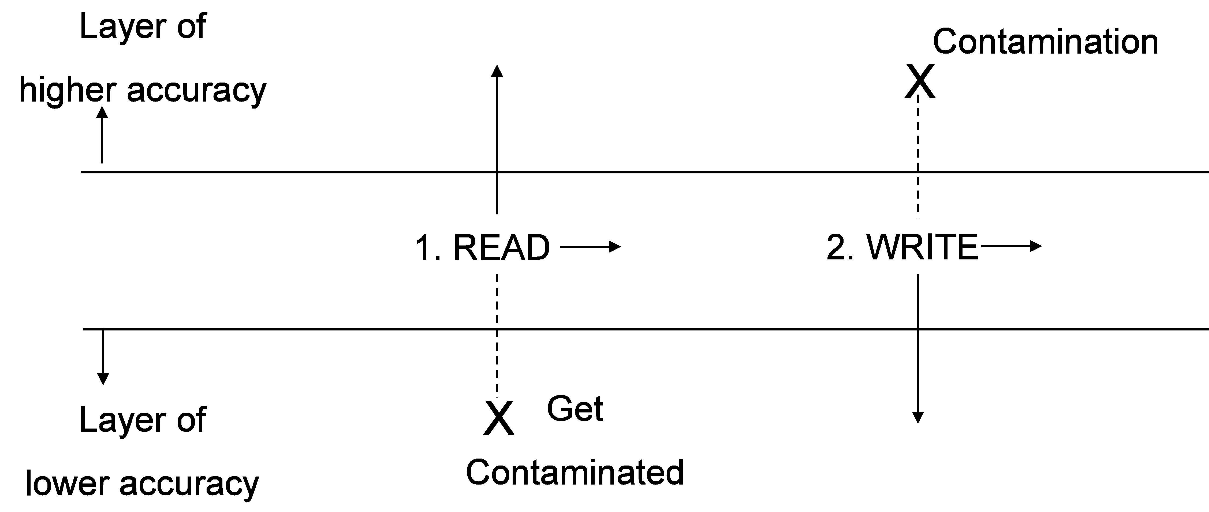
Biba模型解决数据完整性问题,主要防止低完整性级别数据流入高完整性级别,导致高完整性级别数据存在一些不够完整性不足的数据
- 主体不能向位于较高完整性的客体写数据(不向上写)
- 主体不能从较低完整性级别的客体读数据(不像下读)
- 主体只能在同一安全级别上执行读写操作
0x02 RBAC模型设计与实现详解
进入正片,我们主讲RBAC权限模型设计与实现
本文使用Python的Flask框架进行讲解,其他语言Web后台的框架也往往有实现相应功能的API接口
- 代码中
request、response变量可以控制请求和响应包 @xxx.before_app_request可以看作中间件,在每次进入处理逻辑前执行endpoint即对应URL接口,用xxx.yyy表示xxx模块的yyy接口
首先要明确系统有什么样的权限分类,RBAC也只是用户和权限对应的一种优化方式而已,角色这个设定不过是符合社会规则,控制上比较方便灵活,实际上仍然是用户主体和权限对应的关系
因此,我们可以根据系统复杂度,将权限管理设计与实现分为三种类型(->代表对应关系)
- 简单权限分类:
用户->批量权限 - 普通RBAC模型:
用户->角色->权限 - 扩展RBAC模型:
用户->有角色继承有限制器的角色->有限制器的权限
简单权限分类
在大多数的Web系统中,往往只区分未登录用户、登录用户和管理员三种权限,比如部门或者团队单独使用的系统,往往只区分这三种权限就可以满足需求。如果以后业务不会新增权限级别,实际上没有必要适用RBAC模型,将系统管理员模块划分出来,就算在中间件层硬编码用户添加权限管控,也能达到足够的作用,可以在中间件添加如下控制,在每次获得请求进入处理逻辑前执行
@auth.before_app_request
def permission_request():
user = session.get("user", None)
# 未登录用户
if not user:
redirect("auth.login")
# 特权用户与接口
USER_WHITELIST = ["admin1", "admin2", "admin3"]
ENDPOINT_WHITELIST = ["auth.login", "auth.logout"]
if request.endpoint in ENDPOINT_WHITELIST:
if user not in USER_WHITELIST:
abort(403)
# 普通用户与接口不作操作
代码写法可以多样,旨在利用特权的白名单用户和权限去做控制,通过维护白名单去维护权限,新增特权接口和用户必须修改白名单以确定权限修改,避免权限变化时有遗漏
普通RBAC模型
随着业务复杂,权限层级化,在上面这种简单方式不能满足需求的时候,需要其他的结构化管理,比如RBAC模型
回到上面论文中的图
我们根据Web特性和组织结构特性分析一下
- 主体为用户,用普通Web框架自带session和cookie作为主体标识
- 最终客体的权限是URL接口,可细化为operation(操作)和object(数据)两个部分
- 用户和角色多对多关系,角色和权限之间多对多关系
- 根据组织结构层级关系,角色之间可以适用继承关系,低权限角色继承高权限角色部分权限,或者高权限角色继承低权限角色权限,并获得一些新权限
- 权限和角色可以使用一些自定义的限制器
在普通RBAC模型中,我们只用到前3种,不加限制器,角色不继承,权限也不细化
Demo中我们对数据库表的设计大概如图,这里只有一些比较基本的信息,用户角色多对多关系,角色权限多对多关系,这里看个意思就好,对于更多层次的分级和表字段的设计相信各位开发更懂也做得更好
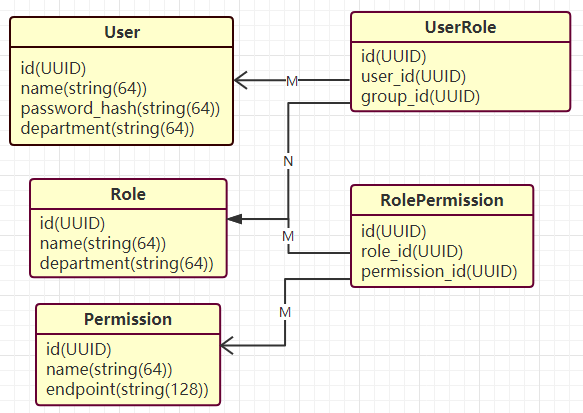
而Flask框架定义endpoint将接口xxx.com/xxx/yyy用别名xxx.yyy表示,也方便了URL变化而接口不变化,我们将这个endpoint的别名作为权限permission表的一个属性,用于识别权限
实现了上面的表关系逻辑后,我们修改上面代码里的中间件逻辑
@auth.before_app_request
def permission_required():
# 未登录用户可访问的白名单
WHITELIST = ["auth.login", "auth.logout", "main.index", "bootstrap.static", "static"]
if request.endpoint in WHITELIST:
return
# 未登录用户访问有限制的接口重定向到登录页面
id = session.get("id", None)
if not id:
return redirect(url_for('auth.login'))
current_user = User.query.filter(User.id==id).first()
permission = Permission.query.filter(Permission.endpoint==request.endpoint).first()
if not current_user.can(permission):
abort(403)
上面代码中查询到endpoint对应的Permission和用户主体后用can函数进行判断,can函数在DAO层实现如下
def can(self, permission):
permissions = []
for role in self.role_list:
permissions.extend(role.permission_list)
if permission in permissions:
return True
return False
简单地说,后台实现表关系,然后实现这样的中间件,权限模型的框架就搭完了,Flask使用url_map函数可以获取所有接口添加到Permission表中,其他框架看情况或者在新增接口时手动录入只是一步操作,也比较方便
再看一下基本的用户界面,直观感受一下怎么控制
用户列表

用户角色编辑
角色列表
角色权限编辑
权限列表
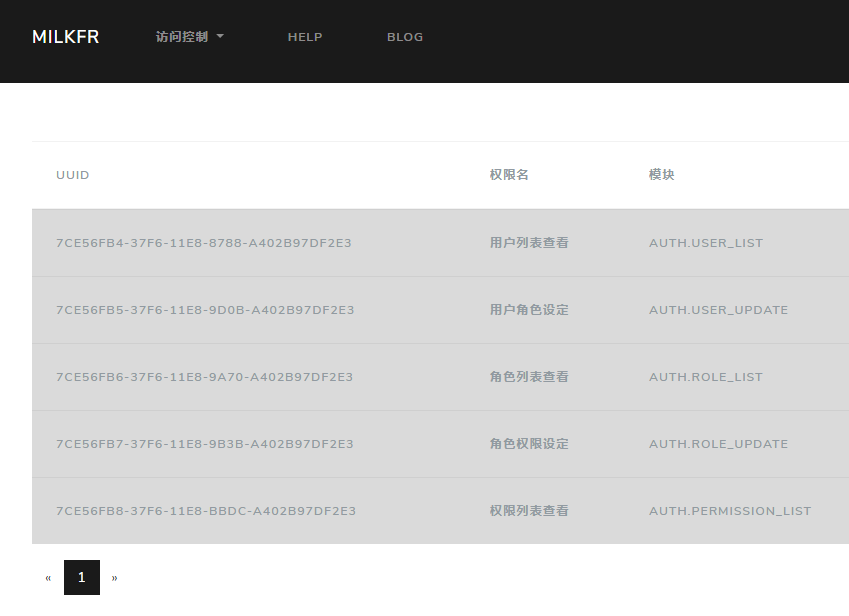
可以由管理员和产品等控制用户角色和权限的关系,而不必修改后台的代码,并且精确到每一个接口,不会有遗漏,所有不经权限判断的接口也有白名单控制,再限制完成以后,就可以看到越权访问时会返回403错误
扩展RBAC模型
上面的普通RBAC模型已经基本涵盖了所有Web授权方面的问题,但仍然有一些不够便利和无法满足的情况
- 角色过多、权限过多是每个角色设置都要点击很多权限选项,操作上不便
- 水平权限问题,对同一接口有访问权限,而对数据有不同
也就是上面一节中提到的我们没有使用的RBAC模型的几种特性
- 根据组织结构层级关系,角色之间可以适用继承关系,低权限角色继承高权限角色部分权限,或者高权限角色继承低权限角色权限,并获得一些新权限
- 最终客体的权限是URL接口,可细化为operation(操作)和object(数据)两个部分
- 权限和角色可以使用一些自定义的限制器
上面说法中角色继承也就是在管理员通过Web前端控制上可以使用继承某个基础角色,就可以获得它的所有权限,然后可以在此基础上新增一些权限,这样就会方便一些,注意:
- 建议单层次角色继承(也就是不会有多级继承)的控制是在前端实现,传到后台的数据不变,表结构也不用,只是前端用户体验更好,建立几个专供继承的基础角色
- 多层次继承时,相当于角色表增加了层级结构,不破坏原有用户、角色、权限的对应关系即可
客体分为operation(操作)和object(数据)两个部分,也导致了水平权限的问题,可以通过增加限制器的方式改善
增加一个Granularity表,作为Permission的粒度控制,关系可一对多或者一对一(实际上一对一应该足够)
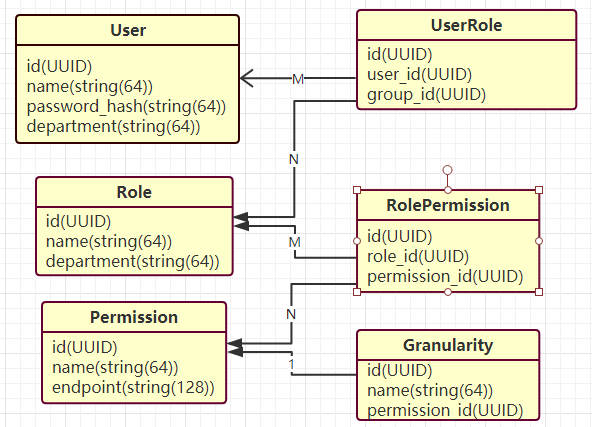
比如水平权限的限制器可以在DAO层增加
granularity = Permissions.get_granularity()
sql = ""
if granularity and model == granularity.name:
sql = "select 1,2,3 from model"
else:
sql = "select 1,2,3,4 from model"
return fetch_data(sql)
上面也是限制器的一种使用方式,处理水平权限问题,如果有其他权限限制,可以增加Granularity表的属性和在其他相应处理逻辑种进行判断
最后再说一下扩展的RBAC模型
- 虽然业务多变但普通RBAC模型已经可以满足绝大多数情况
- 限制器的使用要有良好设计(开发自行设计),没有的话宁愿不要用,比如DAO层进行控制,如果每办法严格做到DAO层的控制,就不要使用,宁可在每个接口进行单独判断水平权限问题,毕竟这样的接口应该不多,不然以为有良好设计,却有地方有疏漏可能造成的结果更不好
TIPS
讲几个注意点
- 登录
- 登录是权限的认证,建议用白名单隔开,单独逻辑处理
- 静态文件
- 前端静态文件可以白名单隔开,但属于用户上传下载的文件仍需要接口做权限判断
- ID随机
- 一些DATA资源的查询ID,建议使用UUID一类的随机数,可以减少在水平权限漏洞出现时被暴破的风险
- 保留日志审计
- 权限系统中增加减少权限、角色变更等操作都要留有日志:包括操作管理人、时间、具体操作等,方便审计
0x03 总结
- RBAC模型是比较通用的解决Web权限问题方法,也比较容易实现
- 了解这个模型的基本实现方式,建议系统设计时加上

