0x00 概述
- 访问控制的认证主要在于使用正确的用户身份认证,在Web系统中也就是Session和Cookie的控制以及对用户口令的限制
- 本文先概述了认证的注意要点,然后举一些我遇到过的有意思的例子说明部分要点存在的问题场景情况
0x01 认证要点
- Password Strength(口令长度)
- 用户口令需要长度和复杂度限制
- 要求用户定期修改密码并防止重用之前的密码
- Password Use(口令使用)
- 限制用户单位时间内尝试登录次数并记录重复失败的登录尝试
- 登录尝试的口令不应该被记录,这可能向任何访问此日志的人公开用户口令
- 登录失败时系统不应该指明用户名或密码是否错误
- 应该提醒用户知道他们上次登录成功的日期和时间,以及从那时起他们账户失败的访问次数
- Password Change Control(口令变化控制)
- 一个只有单一口令验证身份的系统在任何情况下都需要保证用户修改口令操作能力
- 修改口令时,系统需要要求用户提供新旧口令信息
- 如果忘记口令是通过发送给用户电子邮件或手机Token进行验证的,系统应该在用户请求修改邮箱地址和绑定手机号时进一步验证用户身份(打电话或者面核),防止攻击者在临时访问他们会话时(用户登录的时候用他们电脑或者临时借用手机)进行忘记密码等操作
- Password Storage(口令存储)
- 口令需要用加盐哈希或加密的方式保存来避免曝光
- 任何情况下加盐后进行单项散列函数都是首选,因为它不可逆,注意加盐的盐是私盐,每个用户不一样
- 口令不应该被硬编码在任何源代码
- 使用口令时比对加密或哈希后的口令
- 使用加密方式时要严格保护解密密钥
- Password Credentials in Transit(保护传输中的凭据)
- 唯一有效的技术是使用SSL之类的可靠传输协议来加密整个登录过程
- 简单变换的密码(hash或其他)可以截获并转发,即使明文口令可能不知道
- Session ID Protection(保护会话ID)
- 会话ID最大的风险在于在网络中被截获造成的暴露风险,理想情况下,整个会话应该全部通过SSL进行保护
- 无法使用SSL时会话ID必须以其他方式保护
- 不应将会话ID放在URL中,可能会被浏览器缓存、referrer头部或者友站获取或者被不知情用户发送给朋友
- 会话ID应该是长的、复杂的、不容易猜到的随机数
- 会话ID需要在会话期间频繁修改
- 切换到SSL、登录前后和其他主要的会话状态改变是,会话ID必须更改
- Account Lists(账户列表)
- 系统需要被设计为不能被他人访问系统的其他账户信息,防止用户账户信息被遍历,如果因业务一定要公开账户信息,需要对真正的登录信息使用假名(如,显示用户名不显示邮箱,登录时需要邮箱信息而不是用户名信息)
- Browser Caching(浏览器缓存)
- 身份验证和会话数据不应作为GET的一部分提交,应该用POST和Cookie去取代
- 认证页面应该标明HTTP头部的各种无缓存标签,以阻止别人使用浏览器后退按钮重新提交以前输入的凭证
- 许多浏览器支持AUTOCOMPLETE=OFF标签防止自动缓存存储身份凭证信息
- Trust Relationships(信任关系)
- 站点构架应该避免各个组件之间的隐式信任关系,每个组件应该对它所交互的任何其他组件进行身份验证,除非有很强的理由不这样做(比如性能和缺乏可用机制等)
- 如果需要信任关系,应该建立强大的过程和体系结构机制,以确保这种信任不会随站点构架随时间推移而滥用
0x02 案例说明
讲几个我遇到过的案例
变更密码的邮件Token泄露
变更用户密码或绑定手机时会发送一封邮件到用户邮箱,邮件中带有Token信息,邮件内容类似如下信息
感谢您使用XXX通行证,我们已收到为本账号绑定手机的请求,请点击以下链接,完成手机绑定。(此链接24小时内有效)
http://account.xxx.com/bind_mobile?email_sign=k15f5df13dc135ab56f1ecd33cabf8bx39015390f
(如果您无法点击此链接,请将它复制到浏览器地址栏后访问)
1、为了保障您帐号的安全性,请在24小时内完成验证。
2、该链接将在您完成验证后立刻失效。
在实际的开发过程中,邮件发送可能是第三方服务,也有因为开发环境、生产的环境的区别等原因,存在邮件无法发送的情况,而验证这个带有的Token的URL是否可用又需要这个Token,因此,为了方便开发测试,有时候会将Token在用户点击确认后直接发送到前端,开发和测试会直接通过这个Token去拼接URL来绕过邮件中确认。到了生产环境中,这个为了方便的功能没有去掉,邮件确认功能就被绕过失效了。
这个案例是用户变更密码的逻辑漏洞,我们一般认为开发测试为了方便,会留下一些管理台入口或后门等特殊页面,需要监控,而实际上类似这样的测试方便如果没有设计合适的开关,把开发测试环境的内容带到生产环境中,导致认证被绕过,是十分容易被忽略的地方,值得注意。
不安全的Session ID
之前渗透测试企业公众号过程中遇到过这样的请求包
POST /xxx/xxxx/xxxx HTTP/1.1
Host: xxx.xxx.com:443
Accept: application/json, text/plain, */*
X-Requested-With: XMLHttpRequest
Accept-Language: zh-cn
Content-Type: application/x-www-form-urlencoded
Origin: http://xxx.xxx.com:443
User-Agent: Mozilla/5.0 (iPhone; CPU iPhone OS 11_2_6 like Mac OS X) AppleWebKit/604.5.6 (KHTML, like Gecko) Mobile/15D100 MicroMessenger/6.6.5 NetType/WIFI Language/zh_CN
Connection: close
Referer: http://xxx.xxx.com:443/dist/
Content-Length: 121
deviceId=xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx&className=&token=6%2BqD7JRS4MgjJOjumyHdOA%3D%3D
这个请求就很奇怪,它没有Cookie,也就是身份鉴定模块中保存在客户端的信息不用Cookie。除去HTTP的Header,剩下看起来能作为前端用来当用户凭证的信息只有deviceId和token两个参数。也就是说,这个应用很可能是自行设计的身份鉴权模块,而前端的Session ID放在POST参数中
既然如此,我们就要探究deviceId和token两个参数,能不能发现他们的生成方式
一眼看去,token是使用base64编码后结果,但解码后仍然是乱码,也就是用其他方式进行了一次加密或编码,之后再用base64编码获得token。多次抓包发现,token每次请求都会发生变化,而deviceId始终不变,此时猜测token是用于防御CSRF的token或者用来防御重放攻击的时间戳等token,与鉴权无关,鉴权与deviceId有关
进一步去想,企业公众号的鉴权肯定与微信给的接口相关,于是与看微信企业号开发的文档OAuth2.0接入部分说明
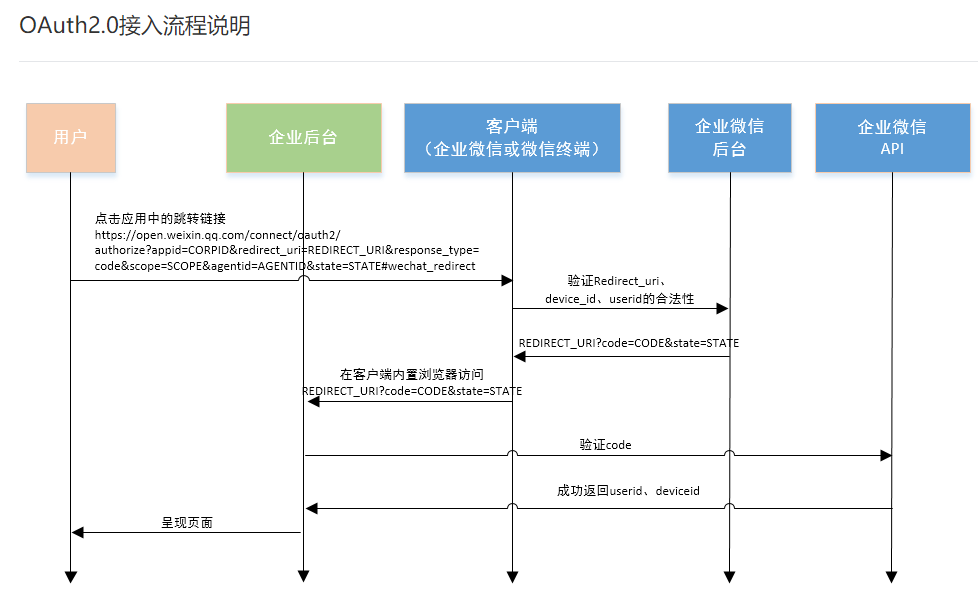
这个流程中存在deviceid这个参数,考虑很可能和所遇项目的deviceid参数一致,结合另一个抓的包
POST /zzzz/zzzz/zzzzz HTTP/1.1
Host: xxx.xxx.com:443
Accept: application/json, text/plain, */*
X-Requested-With: XMLHttpRequest
Accept-Language: zh-cn
Content-Type: application/x-www-form-urlencoded
Origin: http://xxx.xxx.com:443
User-Agent: Mozilla/5.0 (iPhone; CPU iPhone OS 11_2_6 like Mac OS X) AppleWebKit/604.5.6 (KHTML, like Gecko) Mobile/15D100 MicroMessenger/6.6.5 NetType/WIFI Language/zh_CN
Connection: close
Referer: http://xxx.xxx.com:443/dist/?code=FGAQ--dZSSI35fKL0C7-_hQzhMa8Rn8e7KLPrusYiZ0&state=STATE
Content-Length: 48
code=xxxxxxxxxxxxxxxxxxx.......
这里有一个code参数返回,与微信OAuth2.0的code参数格式相似,于是怀疑deviceId和code都是微信提供给企业后台的,但是传回了前端,再去找这两个参数的对应说明
code 通过成员授权获取到的code,最大为512字节。每次成员授权带上的code将不一样,code只能使用一次,5分钟未被使用自动过期
DeviceId 手机设备号(由企业微信在安装时随机生成,删除重装会改变,升级不受影响)
在微信的说明中,code是一个固定时间有效的参数,根据微信文档实际上只能由企业后台保有,不能传输到前端,而DeviceId是手机设备号,长期不变
看到这里,想到利用思路,既然微信客户端安装后DeviceId是不变的,我们重新安装微信客户端,让同事先登录一次这个企业微信公众号,之后让他登出,自己再登录,公众号是否会只返回第一次登录用户的信息呢。经过尝试,确实之后返回第一个登录用户的身份信息页面,之后不管怎么改变登录用户的身份都不会变化,产生了会话固定漏洞。这是可以预见的,毕竟鉴权的Session ID只有这一个
总结一下就是,这个应用存在两个问题
- 企业微信OAuth2.0鉴权返回给企业后台的code参数传到了前端,本该一次性使用的参数暴露出去了(此时应用也没有加上HTTPS)
- 自研的身份鉴权没有认真参考微信的参数,使用DeviceId参数造成了会话固定
最后,我要到了他们的处理代码,找到的token参数的生成方式,看一下主要内容
Long timeNowForServer=new Date().getTime();
if(null!=request.getParameter("token")){
String token=EncryptUtil.aesDecrypt(request.getParameter("token"),"a hard guess string");
if(null!=token) {
Long timeNowForClient = Long.parseLong(token);
//如果请求接口在五秒内
Long timeMinus = timeNowForServer - timeNowForClient;
if (-120000 <= timeMinus && timeMinus <= 120000) {
return true;
} else {
response.sendError(405, "Parameters illegal");
return false;
}
}else{
response.sendError(405, "Parameters illegal");
return false;
}
}else if(request.getRequestURI().indexOf("getUserInfo")>0){
return true;
}else{
response.sendError(405,"Parameters illegal");
return false;
}
看代码可以知道token是一个加密的时间戳,可能是用来防止重放攻击,aesDecrypt是base64解码加aes解密的自定义函数。这就是很奇怪的地方,在细枝末节中加入了aes加密+base64这么复杂的机制,而本身不使用jsession做身份验证,并且在我渗透测试过程中一再和我表示身份验证方式用了很多加密,非常安全… = =
一般渗透过程中看到使用框架本身的身份验证机制一般不会深究,要是发现是自研的,很容易去尝试看有没有问题
总结,除非对密码学一些工具算法和身份验证原理十分清楚了解,不然不推荐使用框架自带机制以外的自研方式,除非有钱愿意自研。使用密码学算法有时会造成很安全的错觉,实际上不正确的使用危险更大
不安全信任关系
当我们使用类似SSO单点登录和OAuth2.0等一下方式在多个系统间进行身份验证的时候,相互之间的信任关系容易引发一些问题
举一个渗透过程中SSO系统的URL跳转漏洞
当我们请求aaa.bbb.com会去到ssohttp.bbb.com进行身份验证,http://ssohttp.bbb.com:8080/cas/login?service=http%3A%2F%2Faaa.bbb.com%2Flogin%2F%3Fnext%3D%252F。登录成功后sso系统会返回http://aaa.bbb.com/login/?next=%2F&ticket=ST-2158-Ku0pEPbnLkUHwebPqAdL-sso.bbb.com
这样带有ticket信息的URL到需要登录的系统,系统检查ticket是否合法确定用户是否存在合法身份
我们使用钓鱼的方式,给普通用户发送这样的URLhttp://ssohttp.bbb.com:8080/cas/login?service=http%3A%2F%2Faaa.hacker.com%2Flogin%2F%3Fnext%3D%252F,将原本的aaa.bbb.com改成aaa.hacker.com这个恶意网站,用户看到熟悉的SSO登录系统登录后,SSO返回的URL变成了http://aaa.hacker.com/login/?next=%2F&ticket=ST-2158-Ku0pEPbnLkUHwebPqAdL-sso.bbb.com,此时我们的恶意网站就接收到了SSO的ticket,然后我们用这个ticket构造正常的URLhttp://aaa.bbb.com/login/?next=%2F&ticket=ST-2158-Ku0pEPbnLkUHwebPqAdL-sso.bbb.com,就可以以被钓鱼用户的身份访问到aaa.bbb.com了
这里的主要问题在于SSO没有对可信任系统进行鉴别,任何系统都可以通过SSO登录,没有对URL进行白名单控制,所以系统不断复杂的情况下,更要注意鉴权系统的每个细节
0x03 再一个例子
这不是一个漏洞的例子,讲一讲我常用的Python Flask框架的session处理方式
在Web中,session是认证用户身份的凭证,它最大也最需要的特点应该就是唯一且不能被伪造(不能在被知道算法的情况下由系统外用户自己生成,被嗅探捕获后仿冒身份则是HTTPS的防御功能)
在传统PHP语言中,通过”PHPSESSID”的Cookie来区分用户,用户看到的是session的名称(一个随机字符串),内容保存在服务端的$_SESSION变量中,这个变量保存在服务端文件中。当然,这是PHP的默认session存储机制,其他Web框架或者语言会有不同,比如Python的Django默认将session存储在数据库中,而Flask是一个微框架,它将session存储在cookie中,用Flask源码中注释的话叫做session based on signed cookies
我们来看看Flask是怎么处理这种session的(写文章时大概是Flask0.12的版本,itsdangerous(Flask的密码学函数库)的0.24版本)
首先看Flask的Session处理代码
class SecureCookieSessionInterface(SessionInterface):
"""The default session interface that stores sessions in signed cookies
through the :mod:`itsdangerous` module.
"""
#: the salt that should be applied on top of the secret key for the
#: signing of cookie based sessions.
salt = 'cookie-session'
#: the hash function to use for the signature. The default is sha1
digest_method = staticmethod(hashlib.sha1)
#: the name of the itsdangerous supported key derivation. The default
#: is hmac.
key_derivation = 'hmac'
#: A python serializer for the payload. The default is a compact
#: JSON derived serializer with support for some extra Python types
#: such as datetime objects or tuples.
serializer = session_json_serializer
session_class = SecureCookieSession
def get_signing_serializer(self, app):
if not app.secret_key:
return None
signer_kwargs = dict(
key_derivation=self.key_derivation,
digest_method=self.digest_method
)
return URLSafeTimedSerializer(app.secret_key, salt=self.salt,
serializer=self.serializer,
signer_kwargs=signer_kwargs)
def open_session(self, app, request):
s = self.get_signing_serializer(app)
if s is None:
return None
val = request.cookies.get(app.session_cookie_name)
if not val:
return self.session_class()
max_age = total_seconds(app.permanent_session_lifetime)
try:
data = s.loads(val, max_age=max_age)
return self.session_class(data)
except BadSignature:
return self.session_class()
def save_session(self, app, session, response):
domain = self.get_cookie_domain(app)
path = self.get_cookie_path(app)
# If the session is modified to be empty, remove the cookie.
# If the session is empty, return without setting the cookie.
if not session:
if session.modified:
response.delete_cookie(
app.session_cookie_name,
domain=domain,
path=path
)
return
# Add a "Vary: Cookie" header if the session was accessed at all.
if session.accessed:
response.vary.add('Cookie')
if not self.should_set_cookie(app, session):
return
httponly = self.get_cookie_httponly(app)
secure = self.get_cookie_secure(app)
samesite = self.get_cookie_samesite(app)
expires = self.get_expiration_time(app, session)
val = self.get_signing_serializer(app).dumps(dict(session))
response.set_cookie(
app.session_cookie_name,
val,
expires=expires,
httponly=httponly,
domain=domain,
path=path,
secure=secure,
samesite=samesite
)
这里主要写了两个函数,一个是save_session,用于将session写入cookie中,一个是open_session,用于获取session类,我们主要看val = self.get_signing_serializer(app).dumps(dict(session))这一句,和get_signing_serializer函数的最后一行return URLSafeTimedSerializer(app.secret_key, salt=self.salt, serializer=self.serializer, signer_kwargs=signer_kwargs)。这里是在get_signing_serializer函数中指定了secret_key、签名用的盐、密钥导出算法、hash函数和系列化方法,然后用这个指定后的签名加序列化方法去处理字典类型的session,重点在于URLSafeTimedSerializer是怎么处理的
我们再去找到这个方法的源码,因为代码太多,有部分没放进来,去掉了loads相关方法,只留下了dumps相关方法
class Signer(object):
# ...
def sign(self, value):
"""Signs the given string."""
return value + want_bytes(self.sep) + self.get_signature(value)
class Serializer(object):
"""This class provides a serialization interface on top of the
signer. It provides a similar API to json/pickle and other modules but is
slightly differently structured internally. If you want to change the
underlying implementation for parsing and loading you have to override the
:meth:`load_payload` and :meth:`dump_payload` functions.
This implementation uses simplejson if available for dumping and loading
and will fall back to the standard library's json module if it's not
available.
Starting with 0.14 you do not need to subclass this class in order to
switch out or customize the :class:`Signer`. You can instead also pass a
different class to the constructor as well as keyword arguments as
dictionary that should be forwarded::
s = Serializer(signer_kwargs={'key_derivation': 'hmac'})
.. versionchanged:: 0.14:
The `signer` and `signer_kwargs` parameters were added to the
constructor.
"""
default_signer = Signer
def __init__(
self, secret_key, salt=b'itsdangerous',
serializer=None, serializer_kwargs=None,
signer=None, signer_kwargs=None
):
self.secret_key = want_bytes(secret_key)
self.salt = want_bytes(salt)
if serializer is None:
serializer = self.default_serializer
self.serializer = serializer
self.is_text_serializer = is_text_serializer(serializer)
if signer is None:
signer = self.default_signer
self.signer = signer
self.signer_kwargs = signer_kwargs or {}
self.serializer_kwargs = serializer_kwargs or {}
def dump_payload(self, obj):
"""Dumps the encoded object. The return value is always a
bytestring. If the internal serializer is text based the value
will automatically be encoded to utf-8.
"""
return want_bytes(self.serializer.dumps(obj, **self.serializer_kwargs))
def make_signer(self, salt=None):
"""A method that creates a new instance of the signer to be used.
The default implementation uses the :class:`Signer` baseclass.
"""
if salt is None:
salt = self.salt
return self.signer(self.secret_key, salt=salt, **self.signer_kwargs)
def dumps(self, obj, salt=None):
"""Returns a signed string serialized with the internal serializer.
The return value can be either a byte or unicode string depending
on the format of the internal serializer.
"""
payload = want_bytes(self.dump_payload(obj))
rv = self.make_signer(salt).sign(payload)
if self.is_text_serializer:
rv = rv.decode('utf-8')
return rv
class TimedSerializer(Serializer):
"""Uses the :class:`TimestampSigner` instead of the default
:meth:`Signer`.
"""
...
class URLSafeSerializerMixin(object):
"""Mixed in with a regular serializer it will attempt to zlib compress
the string to make it shorter if necessary. It will also base64 encode
the string so that it can safely be placed in a URL.
"""
def dump_payload(self, obj):
json = super(URLSafeSerializerMixin, self).dump_payload(obj)
is_compressed = False
compressed = zlib.compress(json)
if len(compressed) < (len(json) - 1):
json = compressed
is_compressed = True
base64d = base64_encode(json)
if is_compressed:
base64d = b'.' + base64d
return base64d
class URLSafeTimedSerializer(URLSafeSerializerMixin, TimedSerializer):
"""Works like :class:`TimedSerializer` but dumps and loads into a URL
safe string consisting of the upper and lowercase character of the
alphabet as well as ``'_'``, ``'-'`` and ``'.'``.
"""
default_serializer = _CompactJSON
URLSafeTimeSerializer继承URLSafeSerializerMinxin和TimedSerializer两个类,而TimedSerializer继承自Serializer,再看Flask中的val = self.get_signing_serializer(app).dumps(dict(session))找到这两个类中的dumps()方法再Serializer类中,dumps()方法使用了dump_payload()方法,在URLSafeTimeSerializer继承的两个父类中都有这个方法,根据Python的多重继承规则与super()方法的使用,整个self.get_signing_serializer(app).dumps(dict(session))的执行过程如下
- json.dumps将对象转换成json字符串,作为需要签名的数据
- 如果数据压缩后长度更短,则用zlib库进行压缩
- 将数据用base64编码
- 通过默认的hmac算法计算数据的签名,将签名附在数据后,用“.”分割
最后,Flask会生成一些类似如下的session_cookie,“.”分割的三个部分分别是session、timestamp和sign
Cookie: session=eyJjc3JmX3Rva2VuIjoiNTdiNjAzZTQ4NjkzNDg5NjYwNzM1NTI1MWIxMDFmNWNlNTliNWZmYiJ9.DbX05w.6eesP-LZF4-zFm8Qey39hHnezGI
Set-Cookie: session=eyJpZCI6IjdjYzNiZjdlLTM3ZjYtMTFlOC1hZmNiLWE0MDJiOTdkZjJlMyIsIm5hbWUiOiJhYWEifQ.DbX1BA.FDO-xc6-JbYO9xle9yytBi1CCpw; HttpOnly; Path=/
Set-Cookie: session=eyJjc3JmX3Rva2VuIjoiMWU2YWYzYWIxMmY4ZjQ0MGNhZjUwNDY0ODZmYjRlYzMwMTMwN2IxNyJ9.DbX1IA.N-na3DOdvaPhlHVdKuPLhO5wNUY; HttpOnly; Path=/
到这里,我们已经完全知道了Flask的session生成编码方式,因此,我们可以将上面这些长串进行解码,还原出session原本的信息,写如下脚本
#!/usr/bin/env python3
import sys
import zlib
from flask.sessions import session_json_serializer
from itsdangerous import base64_decode
def dec(payload):
payload, sig, timestamp = payload.rsplit(b'.', 2)
decompressed = False
if payload.startswith(b'.'):
_, payload = payload.rsplit(b'.')
decompressed = True
payload = base64_decode(payload)
if decompressed:
payload = zlib.decompress(payload)
return session_json_serializer.loads(payload)
if __name__ == '__main__':
print(dec(sys.argv[1].encode()))
还原上面3个session-cookie的信息
$ python test.py eyJjc3JmX3Rva2VuIjoiNTdiNjAzZTQ4NjkzNDg5NjYwNzM1NTI1MWIxMDFmNWNlNTliNWZmYiJ9.DbX05w.6eesP-LZF4-zFm8Qey39hHnezGI
{'csrf_token': '57b603e486934896607355251b101f5ce59b5ffb'}
$ python test.py eyJpZCI6IjdjYzNiZjdlLTM3ZjYtMTFlOC1hZmNiLWE0MDJiOTdkZjJlMyIsIm5hbWUiOiJhYWEifQ.DbX1BA.FDO-xc6-JbYO9xle9yytBi1CCpw
{'id': '7cc3bf7e-37f6-11e8-afcb-a402b97df2e3', 'name': 'aaa'}
$ python test.py eyJjc3JmX3Rva2VuIjoiMWU2YWYzYWIxMmY4ZjQ0MGNhZjUwNDY0ODZmYjRlYzMwMTMwN2IxNyJ9.DbX1IA.N-na3DOdvaPhlHVdKuPLhO5wNUY
{'csrf_token': '1e6af3ab12f8f440caf5046486fb4ec301307b17'}
Flask的Session机制使用hmac签名,防止伪造,满足了session最需要的条件
说一说我对这种机制存在存在问题的理解
- session没有在服务器保存,因为没有expire的时间可以在浏览器端被修改,同一session可以被一直保持使用,这是一个问题,实际上需要在一定时间内进行一次变化,也许Flask有其他机制处理这种问题,我还没有探究到
- 默认条件下Flask的扩展库flask-wtf为了防御CSRF,在session中带上了Flask的
CSRF_TOKEN作为数据,在Flask默认条件下用户的CSRF_TOKEN基础值是不变的,变化的是对CSRF_TOKEN的hmac签名,依靠签名不同来使每次CSRF_TOKEN提交的内容不同,要知道可以通过Cookie直接获得CSRF_TOKEN的基础值,目前来看虽然没有什么问题,但值得注意 - 这里的session_cookie只是经过了编码,而不是加密,要注意这一点,因为乱码很容易给人一种加密的感觉,让人把一些不可泄露的值保存进去,比如将用户口令传到了前端
这一部分将Flask的认证机制单独说明,是想说认证机制往往使用了一些密码学方面的算法,当我们使用一些框架时,即使框架本身是安全的,但如果不了解框架的认证机制,也容易在一些地方产生疏漏,黑盒和盲点越多,可能会出现的问题越大,了解安全认证方式以及自己常用框架的认证方式是十分重要的
0x04 总结
我们说,当我们使用身份认证的时候,我们需要知道我们使用的框架的身份认证机制是否合理,而当我们没有精力去研究框架的时候,我们就使用主流的一些框架。因为主流框架往往经过时间考验且在曝出漏洞时容易被安全部门获得相关信息以便及时防御
作为一个开发者,那就必须牢记:使用强健的加密及签名算法和认证机制,而不是自己想
最后注意校验0x01中的认证要点和自己应用是否符合

