0x00 XWork整体概览
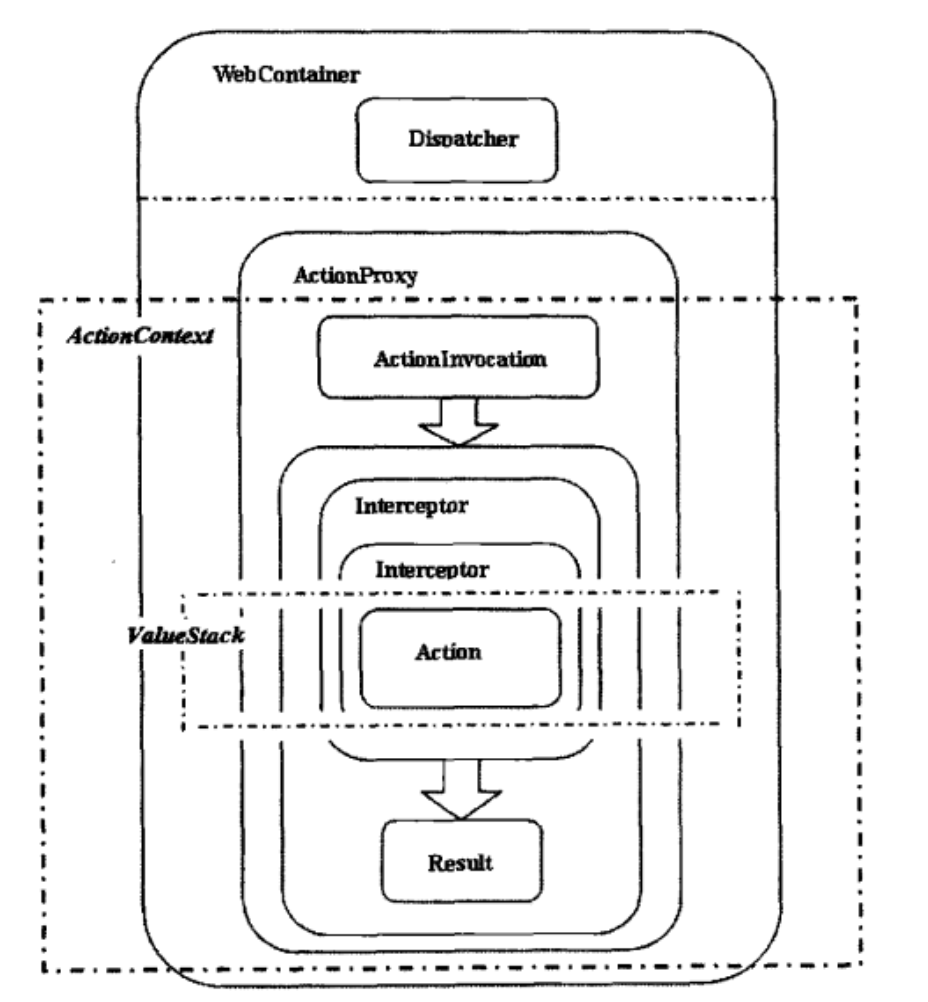
XWork是一个灵活而可靠的给予命令模式的开发框架,所谓命令模式,其本质是请求-响应模式
在我们对Struts2学习的第一篇文章中,就说到了请求-响应模式在Java世界中的实现方式,以及Struts2是使用了POJO模型实现请求响应模式
我们从数据流和控制流两个方向分析
从上图可以看到
XWork的数据流分成两个部分:ActionContext和ValueStack
XWork的控制流分成五个部分:Action、Interceptor、Result、ActionProxy、ActionInnovation
下面我们就来一一分解
0x01 XWork的数据流元素
构成数据流的两大基础功能要求:数据存储(含有数据共享),数据传输
- ActionContext(数据环境):ActionContext是一个独立的数据结构,其主要作用是为XWork的执行提供数据环境,无论是请求的参数,还是处理的返回值,甚至一些原生的Web容器对象,都封装在ActionContext内部,成为Struts2/XWork执行时所依赖的数据基础
- ValueStack(数据访问环境):本身是一个数据结构,主要作用是对OGNL计算进行扩展,因而,位于ActionContext中的ValueStack赋予了ActionContext进行数据计算的功能,从而使得ValueStack自身成为了一个可以进行数据访问的环境
ActionContext用于数据存储和数据共享的容器,ValueStack负责数据传输
ActionContext与ValueStack之间是从属关系,ValueStack是ActionContext的一个组成部分
ActionContext
我们先来看下ActionContext.java中对ActionContext的定义
public class ActionContext implements Serializable {
static ThreadLocal<ActionContext> actionContext = new ThreadLocal<>();
public static final String ACTION_NAME = "com.opensymphony.xwork2.ActionContext.name";
public static final String VALUE_STACK = ValueStack.VALUE_STACK;
public static final String SESSION = "com.opensymphony.xwork2.ActionContext.session";
public static final String APPLICATION = "com.opensymphony.xwork2.ActionContext.application";
public static final String PARAMETERS = "com.opensymphony.xwork2.ActionContext.parameters";
public static final String LOCALE = "com.opensymphony.xwork2.ActionContext.locale";
public static final String TYPE_CONVERTER = "com.opensymphony.xwork2.ActionContext.typeConverter";
public static final String ACTION_INVOCATION = "com.opensymphony.xwork2.ActionContext.actionInvocation";
public static final String CONVERSION_ERRORS = "com.opensymphony.xwork2.ActionContext.conversionErrors";
public static final String CONTAINER = "com.opensymphony.xwork2.ActionContext.container";
private Map<String, Object> context;
public ActionContext(Map<String, Object> context) {
this.context = context;
}
public void setActionInvocation(ActionInvocation actionInvocation) {
put(ACTION_INVOCATION, actionInvocation);
}
public ActionInvocation getActionInvocation() {
return (ActionInvocation) get(ACTION_INVOCATION);
}
public void setApplication(Map<String, Object> application) {
put(APPLICATION, application);
}
public Map<String, Object> getApplication() {
return (Map<String, Object>) get(APPLICATION);
}
public static void setContext(ActionContext context) {
actionContext.set(context);
}
public static ActionContext getContext() {
return actionContext.get();
}
public void setContextMap(Map<String, Object> contextMap) {
getContext().context = contextMap;
}
public Map<String, Object> getContextMap() {
return context;
}
public void setConversionErrors(Map<String, Object> conversionErrors) {
put(CONVERSION_ERRORS, conversionErrors);
}
public Map<String, Object> getConversionErrors() {
Map<String, Object> errors = (Map) get(CONVERSION_ERRORS);
if (errors == null) {
errors = new HashMap<>();
setConversionErrors(errors);
}
return errors;
}
public void setLocale(Locale locale) {
put(LOCALE, locale);
}
public Locale getLocale() {
Locale locale = (Locale) get(LOCALE);
if (locale == null) {
locale = Locale.getDefault();
setLocale(locale);
}
return locale;
}
public void setName(String name) {
put(ACTION_NAME, name);
}
public String getName() {
return (String) get(ACTION_NAME);
}
public void setParameters(HttpParameters parameters) {
put(PARAMETERS, parameters);
}
public HttpParameters getParameters() {
return (HttpParameters) get(PARAMETERS);
}
public void setSession(Map<String, Object> session) {
put(SESSION, session);
}
public Map<String, Object> getSession() {
return (Map<String, Object>) get(SESSION);
}
public void setValueStack(ValueStack stack) {
put(VALUE_STACK, stack);
}
public ValueStack getValueStack() {
return (ValueStack) get(VALUE_STACK);
}
public void setContainer(Container cont) {
put(CONTAINER, cont);
}
public Container getContainer() {
return (Container) get(CONTAINER);
}
public <T> T getInstance(Class<T> type) {
Container cont = getContainer();
if (cont != null) {
return cont.getInstance(type);
} else {
throw new XWorkException("Cannot find an initialized container for this request.");
}
}
public Object get(String key) {
return context.get(key);
}
public void put(String key, Object value) {
context.put(key, value);
}
}
ActionContext用Map类型的变量Context作为真正的数据结构,将所有数据对象用键值的方式存储在context中,也提供了快捷获取对象的方法getValueStack,getSession等
它作为数据存储的容器,存储内容为
- 对XWork框架对象的访问:getContainer、getValueStack、getActionInvocation
- 对数据对象的访问:getSession、getApplication、getParameters等
- 封装了Servlet的原生HttpServletRequest、HttpSession、ServletContext对象,用来解耦框架和Web容器
在数据共享方面,ActionContext考虑了线程安全问题,ActionContext在内部封装了一个静态的TreadLocal的实例,而这个ThreadLocal实例所操作和存储的对象,是ActionContext本身,所以ActionContext是保证实例的线程安全的
ActionContext作为XWork的数据环境,ActionContext的数据内容在整个XWork控制流的生命周期中共享
我们看看程序入口的StrutsPrepareAndExecuteFilter.java
public void doFilter(ServletRequest req, ServletResponse res, FilterChain chain) throws IOException, ServletException {
HttpServletRequest request = (HttpServletRequest)req;
HttpServletResponse response = (HttpServletResponse)res;
try {
String uri = RequestUtils.getUri(request);
if (this.excludedPatterns != null && this.prepare.isUrlExcluded(request, this.excludedPatterns)) {
LOG.trace("Request {} is excluded from handling by Struts, passing request to other filters", new Object[]{uri});
chain.doFilter(request, response);
} else {
LOG.trace("Checking if {} is a static resource", new Object[]{uri});
boolean handled = this.execute.executeStaticResourceRequest(request, response);
if (!handled) {
LOG.trace("Assuming uri {} as a normal action", new Object[]{uri});
this.prepare.setEncodingAndLocale(request, response);
this.prepare.createActionContext(request, response);
this.prepare.assignDispatcherToThread();
request = this.prepare.wrapRequest(request);
ActionMapping mapping = this.prepare.findActionMapping(request, response, true);
if (mapping == null) {
LOG.trace("Cannot find mapping for {}, passing to other filters", new Object[]{uri});
chain.doFilter(request, response);
} else {
LOG.trace("Found mapping {} for {}", new Object[]{mapping, uri});
this.execute.executeAction(request, response, mapping);
}
}
}
} finally {
this.prepare.cleanupRequest(request);
}
}
public void destroy() {
// 这里包含了ActionContext的销毁过程
this.prepare.cleanupDispatcher();
}
可以看到ActionContext在控制流元素之前被构建,并在整个控制流元素执行完毕后被销毁
ActionContext总结
- 保持所有存储对象的Map结构,可以统一数据访问方式
- ActionContext采用了ThreadLocal模式进行数据结构设计,解耦执行逻辑和运行参数
- 横跨了整个XWork的控制流生命周期
ValueStack
先来看看ValueStack.java中对ValueStack的定义
public interface ValueStack {
String VALUE_STACK = "com.opensymphony.xwork2.util.ValueStack.ValueStack";
String REPORT_ERRORS_ON_NO_PROP = "com.opensymphony.xwork2.util.ValueStack.ReportErrorsOnNoProp";
Map<String, Object> getContext();
void setDefaultType(Class var1);
void setExprOverrides(Map<Object, Object> var1);
Map<Object, Object> getExprOverrides();
CompoundRoot getRoot();
void setValue(String var1, Object var2);
void setParameter(String var1, Object var2);
void setValue(String var1, Object var2, boolean var3);
String findString(String var1);
String findString(String var1, boolean var2);
Object findValue(String var1);
Object findValue(String var1, boolean var2);
Object findValue(String var1, Class var2);
Object findValue(String var1, Class var2, boolean var3);
Object peek();
Object pop();
void push(Object var1);
void set(String var1, Object var2);
int size();
}
ValueStack实际上是对OGNL计算的扩展,实际上是针对OGNL三要素中的Root对象进行扩展,扩展方式分为两个步骤
- ValueStack从数据结构的角度被定义为一组对象的集合
- ValueStack规定在自身这个集合中的所有对象,在进行OGNL计算时都被视作Root对象
ValueStack是一个栈结构,同时它是一个典型的装饰器模式,它内部起核心作用的是CompoundRoot数据结构,默认实现类是OgnlValueStack
我们看一下CompoundRoot.java中对CompoundRoot的定义
public class CompoundRoot extends CopyOnWriteArrayList<Object> {
private static final long serialVersionUID = 8563229069192473995L;
public CompoundRoot() {
}
public CompoundRoot(List<?> list) {
super(list);
}
public CompoundRoot cutStack(int index) {
return new CompoundRoot(this.subList(index, this.size()));
}
public Object peek() {
return this.get(0);
}
public Object pop() {
return this.remove(0);
}
public void push(Object o) {
this.add(0, o);
}
}
ValueStack的栈结构是通过CompoundRoot的链表实现的,结合我们说OGNL自身集合在计算时都被视作Root对象,也就是计算时从栈顶往下遍历元素
ValueStack是XWork进行OGNL计算的场所,如果要针对某一对象进行表达式引擎计算,就要将这个对象置于ValueStack中
ValueStack是XWork进行数据访问的基础,如果要通过表达式引擎进行数据访问,ValueStack是重要操作接口
ValueStack支持多个OGNL操作”Root对象”的入口方法的逻辑:XWork无论对于属性访问,还是方法访问都做了重新的过程定义,也就是说,在ValueStack进行OGNL计算时,都会循环扫描CompoundRoot中所有元素,并找到第一个复合表达式定义的元素进行计算,然后返回结果
AppContext和ValueStack的关系
ActionContext的创建总是伴随着ValueStack的创建,ValueStackFactory负责创建ValueStack,并为ValueStack设置上下文环境,紧接着ValueStack负责创建的就是ActionContext,并且ActionContext的创建以ValueStack的上下文作为参数,可见,ValueStack的构建是ActionContext构建的基础,两者总是在几乎相通的时刻被创建出来
ValueStack的OGNL三要素之一的上下文环境与ActionContext的数据存储空间是等同的,也就是OGNL几乎可以控制ActionContext的所有数据结构
DefaultActionInvocation.java
public void init(ActionProxy proxy) {
// 省略了一些代码
if (pushAction) {
stack.push(action);
contextMap.put("action", action);
}
// 省略了一些代码
}
控制流中的核心元素Action,被置于数据流元素ValueStack中
传统请求-响应模型中,无论是参数-返回值模式还是参数-参数模式,控制流元素对应数据流元素都是有决定的掌控权的,XWork中,控制流的核心元素反而反过来置于数据流中
这使得这一核心元素可以完全摆脱对Web容器的依赖,由一个无状态的响应对象变成一个有状态的POJO,其次,在控制流的核心元素执行时,由于它身处于数据流元素的包围之中,因而它又能够轻而易举地对数据流元素随取随用
0x02 XWork的控制流元素
控制流的继承功能要求:划分事件处理流程,定义事件处理的节点,组织事件处理节点对象的执行次序,
- Action(核心处理类):是XWork所定义的一个核心的事件处理接口,定义了一个没有参数的响应方法,响应方法内部完成对核心业务的处理,而事件类的内部属性则成为响应方法进行业务处理的数据来源和响应结果
- Interceptor(拦截器):Interceptor本身是AOP的概念,表示对程序某个逻辑执行点进行拦截,从而能够在这个逻辑执行点之前、之后或者环绕着这个逻辑执行点进行逻辑扩展,Interceptor拦截对象是Action
- Result(执行结果):Result是XWork定义的用以对核心处理类Action执行完毕后的响应处理动作,Result被定义成一个独立的逻辑执行层次,其主要作用是使用核心处理类Action能够更加关注核心业务流程的处理,将程序的跳转控制逻辑交给Result来完成
- ActionProxy(执行环境):ActionProxy是整个XWork框架的执行入口,ActionProxy的存在,相当于定义了一个事件处理流程的执行范围,规定在ActionProxy内部的一切都属于XWork框架的管辖范围,在ActionProxy之外,只能以调用者身份,与整个XWork的事件执行体系进行通信,因此,ActionProxy主要作用就是对外屏蔽整个控制流核心元素的执行过程,对内则为Action、Interceptor、Result等事件处理节点提供一个无干扰的执行环境
- ActionInvocation(核心调度器):ActionInvocation是组织起Action、Interceptor、Result等事件处理节点对象执行次序的核心调度器,被封装于ActionProxy内部,是XWork内部真正事件处理的司令
一个完整事件处理流程可以定义为:Action为业务处理核心,Interceptor进行逻辑辅助,Result进行响应逻辑跳转的具有丰富执行层次的事件处理体系,因此Action、Interceptor和Result是划分事件处理流程和定义事件处理节点的功能
ActionProxy和ActionInvocation是最关键的组织事件处理节点对象的执行次序这个功能
ActionProxy(执行窗口)
ActionProxy是XWork事件处理框架的总代理
我们从web.xml中定义StrutsPrepareAndExecuteFilter类的doFilter方法->ExecuteOperations类的executeAction方法->Dispatcher类的serviceAction方法
serviceAction中创建了ActionProxy方法:ActionProxy proxy = ((ActionProxyFactory)this.getContainer().getInstance(ActionProxyFactory.class)).createActionProxy(namespace, name, method, extraContext, true, false);
我们来看一下ActionProxy的定义
public interface ActionProxy {
// 当前ActionProxy代理的Action读对象
Object getAction();
String getActionName();
ActionConfig getConfig();
void setExecuteResult(boolean executeResult);
boolean getExecuteResult();
ActionInvocation getInvocation();
// 当前ActionProxy对应的配置文件的namespace值
String getNamespace();
String execute() throws Exception;
// 获取Action对象中进行请求响应的方法名称,空则使用默认的execute方法
String getMethod();
boolean isMethodSpecified();
}
ActionProxy的定义中有与众多配置元素相关的操作接口,它的首要指责是维护XWork的执行元素与请求对象之间的配置映射关系
再来看一下ActionProxy的创建过程
public ActionProxy createActionProxy(String namespace, String actionName, String methodName, Map<String, Object> extraContext, boolean executeResult, boolean cleanupContext) {
ActionInvocation inv = createActionInvocation(extraContext, true);
container.inject(inv);
return createActionProxy(inv, namespace, actionName, methodName, executeResult, cleanupContext);
}
- 配置映射关系:namespace、actionName、methodName,明确ActionProxy与具体的XWork执行元素之间的配置关系
- 运行上下文环境:extraContext,Map结构
ActionProxy差不多就这样
ActionInvocation(调度核心)
先看一下ActionInvocation的定义
public interface ActionInvocation {
Object getAction();
boolean isExecuted();
ActionContext getInvocationContext();
ActionProxy getProxy();
Result getResult() throws Exception;
String getResultCode();
void setResultCode(String resultCode);
ValueStack getStack();
// 注册一个PreResultListener的实现类,这个类中的扩展逻辑将于Action对象执行完毕,Result对象执行之前执行
void addPreResultListener(PreResultListener listener);
// 核心调度
String invoke() throws Exception;
// 单个Action的调度
String invokeActionOnly() throws Exception;
void setActionEventListener(ActionEventListener listener);
void init(ActionProxy proxy) ;
}
ActionInvocation的功能分类
- 对控制流元素和数据流元素的访问接口:getAction、getActionProxy、getStack等
- 对执行调度流程的扩展接口:addPreListener、setActionEventListener
- 对执行栈进行调度执行的接口:invoke、invokeActionOnly
看DefaultActionInnovation中invoke的实现
public String invoke() throws Exception {
String profileKey = "invoke: ";
try {
UtilTimerStack.push(profileKey);
if (executed) {
throw new IllegalStateException("Action has already executed");
}
if (interceptors.hasNext()) {
final InterceptorMapping interceptorMapping = interceptors.next();
String interceptorMsg = "interceptorMapping: " + interceptorMapping.getName();
UtilTimerStack.push(interceptorMsg);
try {
Interceptor interceptor = interceptorMapping.getInterceptor();
if (interceptor instanceof WithLazyParams) {
interceptor = lazyParamInjector.injectParams(interceptor, interceptorMapping.getParams(), invocationContext);
}
resultCode = interceptor.intercept(DefaultActionInvocation.this);
} finally {
UtilTimerStack.pop(interceptorMsg);
}
} else {
resultCode = invokeActionOnly();
}
// this is needed because the result will be executed, then control will return to the Interceptor, which will
// return above and flow through again
if (!executed) {
if (preResultListeners != null) {
LOG.trace("Executing PreResultListeners for result [{}]", result);
for (Object preResultListener : preResultListeners) {
PreResultListener listener = (PreResultListener) preResultListener;
String _profileKey = "preResultListener: ";
try {
UtilTimerStack.push(_profileKey);
listener.beforeResult(this, resultCode);
}
finally {
UtilTimerStack.pop(_profileKey);
}
}
}
// now execute the result, if we're supposed to
if (proxy.getExecuteResult()) {
executeResult();
}
executed = true;
}
return resultCode;
}
finally {
UtilTimerStack.pop(profileKey);
}
}
invoke是核心方法,大致意思是将Interceptor对象和Action对象共同构成的执行栈进行逻辑执行调度
- 如果执行栈的下一个元素是Interceptor对象,那么执行该Interceptor的intercept方法
- 如果执行栈的下一个元素是Action对象,那么执行该Action对象的方法
- 如果执行栈中找不到下一个执行元素,那么执行终止,返回执行结果ResultCode
- 有了ResultCode后执行executeResult
resultCode = interceptor.intercept(DefaultActionInvocation.this);,ActionInvocation调用了拦截器的intercept方法,拦截器调用了ActionInvocation的invoke方法,形成了递归调用
我们跟踪executeResult会最后到达Result创建流程,这个过程我们之后讲解Result的时候再将
这里,我就完成了ActionInnovation调度Interceptor、Action和Result的过程
Action
在我们对Struts2学习的第一篇文章中,就说到了请求-响应模式在Java世界中的实现方式,以及Struts2是使用了POJO模型实现请求响应模式
Action使用了POJO模式的实现,这里不多说明了,看一下定义就好
public interface Action {
public static final String SUCCESS = "success";
public static final String NONE = "none";
public static final String ERROR = "error";
public static final String INPUT = "input";
public static final String LOGIN = "login";
public String execute() throws Exception;
}
Interceptor
Interceptor是原本属于AOP(面向切面编程)中的概念,其本质是一个代码段,可以通过定义织入点(一个特定的编程元素,既可以是对象,也可以是对象中的方法),来指定Interceptor的代码逻辑在织入点元素之前或者之后执行,从而起到拦截的作用
AOP的相关概念
切面(Aspect):一个关注点的模块化,这一关注点的实现可以横切多个对象,而这个模块化的过程,由Interceptor实现,如数据的事务管理就是一个典型的切面 通知(Advice):在特定的连接点,AOP框架执行的动作,各种通知类包括Before、After、Around、Throw通知等 切入点(Pointcut):指定一个通知将被引发的一系列连接点的集合,AOP框架允许开发者指定切入点,例如,使用正则表达式来指定出发通知的集合特征 连接点(Joinpoint):程序执行过程中明确的点,如方法的调用或特定的异常被抛出
Interceptor的概念与基本的AOP概念之间的对应关系
- 切面(Aspect):Interceptor实现
- 通知(Advice):环绕通知(Around通知)
- 切入点(Pointcut):Action对象
- 连接点(Joinpoint):Action的执行
所以,XWork中的Interceptor,是一组环绕在切入点(Action对象)的执行切面,可以在Action调用之前或者调用之后执行,从而对Action对象起到拦截作用
Interceptor.java
public interface Interceptor extends Serializable {
void destroy();
void init();
String intercept(ActionInvocation var1) throws Exception;
}
其他任意Interceptor的继承实现类
@Override
public String intercept(ActionInvocation invocation) throws Exception {
before(invocation);
result = invocation.invoke();
after(invocation, result);
return result;
}
Interceptor和intercept使用ActionInvocation作为参数是为了
- 便于Interceptor随时与控制流和数据流的其他元素沟通
- 便于ActionInvocation在Interceptor内部进行执行调度
找到ActionInvocation的invoke,上面的分析有,这个方法在InterceptorMapping的下一个Interceptor.intercept方法,而interceptor由调用ActionInnovation.invoke,形成了一个递归调用的循环,直到触发了所有Interceptor的intercept,才会调用Action的方法
Result
先看一下Result的定义
public interface Result extends Serializable {
public void execute(ActionInvocation invocation) throws Exception;
}
非常简单,甚至不知道干了什么
看一看上面ActionInvocation的executeResult
private void executeResult() throws Exception {
result = createResult();
String timerKey = "executeResult: " + getResultCode();
try {
UtilTimerStack.push(timerKey);
if (result != null) {
result.execute(this);
} else if (resultCode != null && !Action.NONE.equals(resultCode)) {
throw new ConfigurationException("No result defined for action " + getAction().getClass().getName()
+ " and result " + getResultCode(), proxy.getConfig());
} else {
if (LOG.isDebugEnabled()) {
LOG.debug("No result returned for action {} at {}", getAction().getClass().getName(), proxy.getConfig().getLocation());
}
}
} finally {
UtilTimerStack.pop(timerKey);
}
}
创建result后执行它的execute方法
举个例子是我们可以看PlainTextResult.java,这个文件在org.apache.struts2中,不再xwork包内
public class PlainTextResult extends StrutsResultSupport {
protected void doExecute(String finalLocation, ActionInvocation invocation) throws Exception {
// verify charset
Charset charset = readCharset();
HttpServletResponse response = (HttpServletResponse) invocation.getInvocationContext().get(HTTP_RESPONSE);
applyCharset(charset, response);
applyAdditionalHeaders(response);
String location = adjustLocation(finalLocation);
try (PrintWriter writer = response.getWriter();
InputStream resourceAsStream = readStream(invocation, location);
InputStreamReader reader = new InputStreamReader(resourceAsStream, charset == null ? Charset.defaultCharset() : charset)) {
logWrongStream(finalLocation, resourceAsStream);
sendStream(writer, reader);
}
}
}
这里StrutsResultSupport继承了Result,doExecute相当于Result.execute的封装,可以看到相当于是获取HttpServletResponse,并进行了读写操作
这里说明一下,这里的PlainTextResult.java属于Struts2,而不是XWork,因为在XWork的视角看Result对象,它是我们对事件处理流程步骤的划分结果,是进行收尾的元素,而Struts2的视角,Result是用来操作HttpServletResponse的,而Struts2为了将Web容器和XWork解耦,所以需要对XWork透明Result
到这里XWork的控制流和数据流就解读完成了,回头看一下文章一开始的图片,是不是觉得清晰很多了
0x03 XWork中的容器
这一节做一个补充,讲一下容器的知识,因为不止在Struts2中,Tomcat等很多Java大型程序都有这个概念,理解了以后感觉很有帮助
- 在程序运行期间,对象实例的创建和引用机制
- 对象与其关联对象的依赖关系的处理机制,尤其反转控制的提出对我们编程提出额外的要求
控制反转(Inverse of Control)是对象生命周期管理中的一个核心概念,并以此为基础创造了一个大家更为熟悉和理解的概念:依赖注入(Dependency Injection)
每个对象自身对于逻辑的执行能力,被其所依赖的对象反向控制了,这也就是控制反转的本质含义
控制反转概念的提出对我们编程程序提出了额外的要求,因为我们不得不去实现”获取依赖对象”这一基本的逻辑功能,从而使得对象与对象之间的协作和沟通变得更为畅通
实现获取依赖对象这个过程,如果让程序自身处理,存在3个弊端
- 对象将频繁创建,效率大大降低(尽管在大多数情况下,这些对象都是无状态的单例对象)
- 对象的创建逻辑与业务逻辑代码高度耦合,使得一个对象的逻辑关注度大大分散
- 程序的执行效率大大降低,由于无法区分明确的指责,很难针对对象实现业务逻辑进行单元测试
这些问题不仅是面向对象编程语言中的核心问题,也是每个框架在进行设计时必须跨越的坎
业界对这样的问题也早有公论:为了更好地管理好对象的生命周期,我们有必要在程序逻辑中引入一个额外的编程元素,这个元素就是容器(Container),用这个与具体业务逻辑完全无关的额外的编程元素容器来帮助进行对象的生命周期管理
容器的设计
容器(Container)由一系列对象的操作接口构成,其中应该至少包含获取对象实例以及管理对象之间的依赖关系这两类操作方法
因此容器的接口定义大概需要满足以下条件
- 容器应该被设计成一个全局的、统一的编程元素,它在整个系统中应该被实例化为一个全局的、单例的对象
- 在最大程度上降低容器对业务逻辑的入侵
- 容器应该提供简单而全面的对象操作接口
XWork根据以上要求对容器做了以下定义
public interface Container extends Serializable {
String DEFAULT_NAME = "default";
void inject(Object o);
<T> T inject(Class<T> implementation);
<T> T getInstance(Class<T> type, String name);
<T> T getInstance(Class<T> type);
Set<String> getInstanceNames(Class<?> type);
void setScopeStrategy(Scope.Strategy scopeStrategy);
void removeScopeStrategy();
}
容器定义了以下几种类型的方法,非常简答
- 获取对象实例:getInstance、getInstanceName
- 处理对象依赖关系:inject
- 处理对象的作用范围策略:setScopeStrategy、removeScopeStrategy
容器的数据结构
XWork的容器被定义成一个接口,其内部封装了一组操作方法,它并不是一个具体的数据结构,那它内部的数据结构是什么样子呢
我们从对象制造工厂和注入器两个方面介绍XWork容器的实现机理
我们看一下容器的实现类ContainerImpl.java
class ContainerImpl implements Container {
final Map<Key<?>, InternalFactory<?>> factories;
final Map<Class<?>, Set<String>> factoryNamesByType;
ContainerImpl(Map<Key<?>, InternalFactory<?>> factories) {
this.factories = factories;
Map<Class<?>, Set<String>> map = new HashMap<>();
for (Key<?> key : factories.keySet()) {
Set<String> names = map.get(key.getType());
if (names == null) {
names = new HashSet<>();
map.put(key.getType(), names);
}
names.add(key.getName());
}
for (Entry<Class<?>, Set<String>> entry : map.entrySet()) {
entry.setValue(Collections.unmodifiableSet(entry.getValue()));
}
this.factoryNamesByType = Collections.unmodifiableMap(map);
}
}
从源码中,我们可以到ContainerImpl内部所封装的两个内部实例变量:factories和factoryNamesByType,它们都是Map结构,其中factories是由构造函数传递进入并缓存于内部,而factoryNamesByType则在factories的基础之上做了一个根据名称进行寻址的缓存映射关系
从factories的key的type和name两个属性,我们马上可以对应上struts-default.xml中的配置,事实上也确实如此,type和name对应不同实现类关系
<bean type="com.opensymphony.xwork2.factory.ResultFactory" name="struts" class="org.apache.struts2.factory.StrutsResultFactory" />
在Struts2的配置中,有bean和constant两类节点,这两个节点统称为”容器配置元素”,另外一类package节点,称为”事件映射关系”,我们进行配置元素分类的基本思路是按照XML节点所表达的逻辑含义和该节点在程序中所起的作用来进行
XWork容器所管理的对象包括所有框架配置定义中的”容器配置元素”
- bean节点中声明的框架内部对象
- bean节点中声明的自定义对象
- 在constant节点和Properties文件中声明的系统运行参数
然后我们看看factories的value的,它的具体实现类型是InternalFactory
interface InternalFactory<T> extends Serializable {
T create(InternalContext var1);
}
这个泛型的接口只有一个create方法,也就是说:一旦实现这个接口,我们就需要指定对象的创建机制,由此可见,factories中存储的内容,是Java对象(type所指向的Java类)的实例构建方法
在容器内部进行缓存的是对象实例的构建方法,而不是对象实例本身,这就让容器看起来像一个工厂的集合,能够根据不同的要求,制造出不同种类的对象实例
容器之所以不被具体定义成一个具体的数据结构类而被定义成一系列操作接口的真正原因是:它的内部的确就是一个工厂
除此之外,当调用容器的inject方法来实施依赖注入操作时,所操作的对象确不仅仅限于”容器配置元素”中所定义的对象,因为inject方法的定义是,只要传入一个实例,容器将负责建立起传入对象实例与容器托管对象之间的依赖关系
调用XWork容器的inject方法,能够帮助我们将容器所管理的对象(包括框架的内置对象以及系统的运行参数)注入到任意的对象实例中去,从而建立起任意对象与框架元素沟通的桥梁
@Target({METHOD, CONSTRUCTOR, FIELD, PARAMETER})
@Retention(RUNTIME)
public @interface Inject {
/**
* @return Dependency name. Defaults to {@link Container#DEFAULT_NAME}.
*/
String value() default DEFAULT_NAME;
/**
* @return Whether or not injection is required. Applicable only to methods and
* fields (not constructors or parameters).
*/
boolean required() default true;
}
当我们需要寻求容器当帮助时,在恰当的地方加入一个注解标识符,容器在进行依赖注入操作时,就能够知晓并接管整个过程了
这里我们解答了一个核心问题:如何建立起系统到容器或者容器托管对象的沟通强梁——通过@Inject声明来完成
那么如何实施对象的依赖注入
除了获取对象实例之外,XWork容器的另一个充要的操作接口是”实施对象的依赖注入”操作,因此,从数据结构的角度讲,XWork容器的内部除了缓存一个对象制造工厂factories用以在运行期间能够创建对象实例并返回之外,还需要另一类缓存的帮助,这类缓存用于记录对象与对象之间的依赖关系,称之为注入器(Injector)
class ContainerImpl implements Container {
final Map<Class<?>, List<Injector>> injectors = new ReferenceCache<Class<?>, List<Injector>>() {
@Override
protected List<Injector> create(Class<?> key) {
List<Injector> injectors = new ArrayList<>();
addInjectors(key, injectors);
return injectors;
}
};
interface Injector extends Serializable {
void inject(InternalContext context, Object o);
}
void addInjectors(Class clazz, List<Injector> injectors) {
if (clazz == Object.class) {return;}
// 首先递归调用自身,以完成对父类的注入器查找
addInjectors(clazz.getSuperclass(), injectors);
// 针对所有属性查找满足条件的注入器,并加入到injectors中进行缓存
addInjectorsForFields(clazz.getDeclaredFields(), false, injectors);
// 针对所有方法查找满足条件的注入器,并加入到injectors中进行缓存
addInjectorsForMethods(clazz.getDeclaredMethods(), false, injectors);
}
// 针对所有方法查找满足条件的注入器,并加入到injectors中进行缓存
void addInjectorsForMethods(Method[] methods, boolean statics, List<Injector> injectors) {
addInjectorsForMembers(Arrays.asList(methods), statics, injectors,
new InjectorFactory<Method>() {
public Injector create(ContainerImpl container, Method method,String name) throws MissingDependencyException {
return new MethodInjector(container, method, name);
}
}
);
}
// 针对所有属性查找满足条件的注入器,并加入到injectors中进行缓存
void addInjectorsForFields(Field[] fields, boolean statics, List<Injector> injectors) {
addInjectorsForMembers(Arrays.asList(fields), statics, injectors,
new InjectorFactory<Field>() {
public Injector create(ContainerImpl container, Field field,String name) throws MissingDependencyException {
return new FieldInjector(container, field, name);
}
}
);
}
// 统一的Injector查找方式
<M extends Member & AnnotatedElement> void addInjectorsForMembers(
List<M> members, boolean statics, List<Injector> injectors, InjectorFactory<M> injectorFactory) {
for (M member : members) {
if (isStatic(member) == statics) {
Inject inject = member.getAnnotation(Inject.class);
if (inject != null) {
try {
injectors.add(injectorFactory.create(this, member, inject.value()));
} catch (MissingDependencyException e) {
if (inject.required()) {
throw new DependencyException(e);
}
}
}
}
}
}
......
}
ReferenceCache是一种缓存的简单实现,它提供一种在运行期构建Map内容的机制,ReferenceCache中维护着一个ConcurrentMap,并且在内部应用ThreadLocal模式很好地规避了对象操作的多线程问题
有了ReferenceCache,我们操作Map的方式会有所改变,调用Map中接口的get时,ReferenceCache会首先查找其内部是否已经存在相应的缓存对象,存在则返回,不存在则调用其抽象方法create根据key的内容产生对象并缓存起来
注入器是一个ReferenceCache缓存,Key是每一个Class对象,Value是根据Class对象查找到的所有隶属于Class中的注入器,Key和Value之间的建立过程,通过ReferenceCache中的create方法完成
从上面源码中可以看到,无论属性还是方法,最后通过addInjectorsForMembers方法,然后使用member.getAnnotation(Inject.class)获取加上@Inject这个注解的属性或者方法,任一对象,凡是加上@Inject这个注解的属性或者方法都会被初始化相应的注入器,并调用Container的inject方法实施依赖注入
这样我们就了解的XWork容器内部两个主要的数据结构factories和injectors
XWork容器的操作
通过一个例子,在ActionSupport中的两个函数看看框架是如何使用容器的
public class ActionSupport implements Action, Validateable, ValidationAware, TextProvider, LocaleProvider, Serializable {
protected TextProvider getTextProvider() {
if (textProvider == null) {
Container container = getContainer();
TextProviderFactory tpf = container.getInstance(TextProviderFactory.class);
textProvider = tpf.createInstance(getClass());
}
return textProvider;
}
@Inject
public void setContainer(Container container) {
this.container = container;
}
}
很明显,getTextProvider是以setContainer的存在为基础,@Inject这个注解的使用,使得setContainer这个方法在ActionSupport初始化时被注入全局的Container对象,而getTextProvider是在运行期被调用
所以@Inject注解的函数的意义是:在当前的对象操作主体进行初始化时,这个方法会被调用,而全局的容器对象则会被初始化到当前的对象操作主体之中
在ContainerImpl中使用模版方法将所有接口操作进行规范化定义,同时将它们纳入一个线程安全的上下文环境
<T> T callInContext(ContextualCallable<T> callable) {
Object[] reference = localContext.get();
if (reference[0] == null) {
reference[0] = new InternalContext(this);
try {
return callable.call((InternalContext) reference[0]);
} finally {
// Only remove the context if this call created it.
reference[0] = null;
// WW-3768: ThreadLocal was not removed
localContext.remove();
}
} else {
// Someone else will clean up this context.
return callable.call((InternalContext) reference[0]);
}
}
public void inject(final Object o) {
callInContext(new ContextualCallable<Void>() {
public Void call(InternalContext context) {
inject(o, context);
return null;
}
});
}
public <T> T getInstance(final Class<T> type, final String name) {
return callInContext(new ContextualCallable<T>() {
public T call(InternalContext context) {
return getInstance(type, name, context);
}
});
}
如上面源码所示,很容易理解
具体到inject和getInstance的实现
getInstance主要是通过name和type构成的key去获取InternalFactory实现,通过其内部缓存的factories对象寻址,使用InternalFactory规定的对象构建方法返回对象实例
inject主要是通过在容器内部根据type和name进行对象构造工厂factory的寻址,之后inject调用过程,只不过是调用factory构建对象,并使用Java中最为普遍的反射机制来完成对象的依赖注入,被初始化进injectors
容器自身的inject包含两个非常简单的步骤:查找当前对象所需要被注入的字段或者方法以及调用相应的injector实现类进行依赖注入
ObjectFactory——统一的容器操作接口
对象的创建和对象的依赖注入是对象生命周期管理的两个不同的方面,在我们创建一个新的对象之后,往往会调用Container中的inject方法为这个对象进行依赖注入的操作
XWork提供类一个工具类ObjectFactory,允许程序员在程序的运行期动态地构建一个新的对象,并且为这个新构建的对象实施依赖注入操作
ObjectFactory提供了两类具有代表性的工具方法:
- 构建XWork框架内部对象Action、Interceptor、Result和Validator的快捷方法
- 构建一个普通bean和核心方法buildBean,包含了对象创建和依赖注入两个核心过程,也成为一个统一的对象初始化操作接口,其他工具方法,最终实施对象构建都是使用核心的buildBean方法
ObjectFactory的意义
- 全部使用ObjectFactory进行框架内置对象的构建保证了所有XWork框架中执行对象都受到XWork容器的管理
- ObjectFactory成为了自定义Bean和Struts2的固有组件或者内置对象对话的窗口,也是对Struts2现有功能进行有机扩展的必要元素
ObjectFactory和Container的联系与区别
- Container对象在Struts2进行初始化的时候被创建出来,其中包含了所有在Struts2应用中定义的对象的构造工厂,从而保证了在运行期,当我们需要获得一个已定义好的内置对象时,可以通过Container的接口完成,所以,针对Container的操作,以读取为主
- ObjectFactory对象则偏重于在程序运行过程中的对象构建,并且提供了一个与Struts2容器进行交互的窗口,因此,ObjectFactory创建出来的对象往往是一个运行期的新对象而非一个”单例”的工具对象,这与我们在容器中定义的许多对象都是不同的,所以,针对ObjectFactory的操作,以构建为主

