0x00 UNIX系统的I/O模型
当用户线程发起I/O操作后,比如网络数据读取过程会经历两个步骤:
- 用户线程等待内核将数据从网卡拷贝到内核空间
- 内核将数据从内核空间拷贝到用户空间
I/O模型是为了解决内存和外部设备速度差异的问题,我们常说的阻塞和非阻塞是指应用程序在发起I/O操作时,是立即返回还是等待,同步和异步是在与内核通信时,数据从内核空间到应用空间的拷贝,是由应用程序来触发还是由内核发起
0x01 4种类型I/O模型
同步阻塞I/O
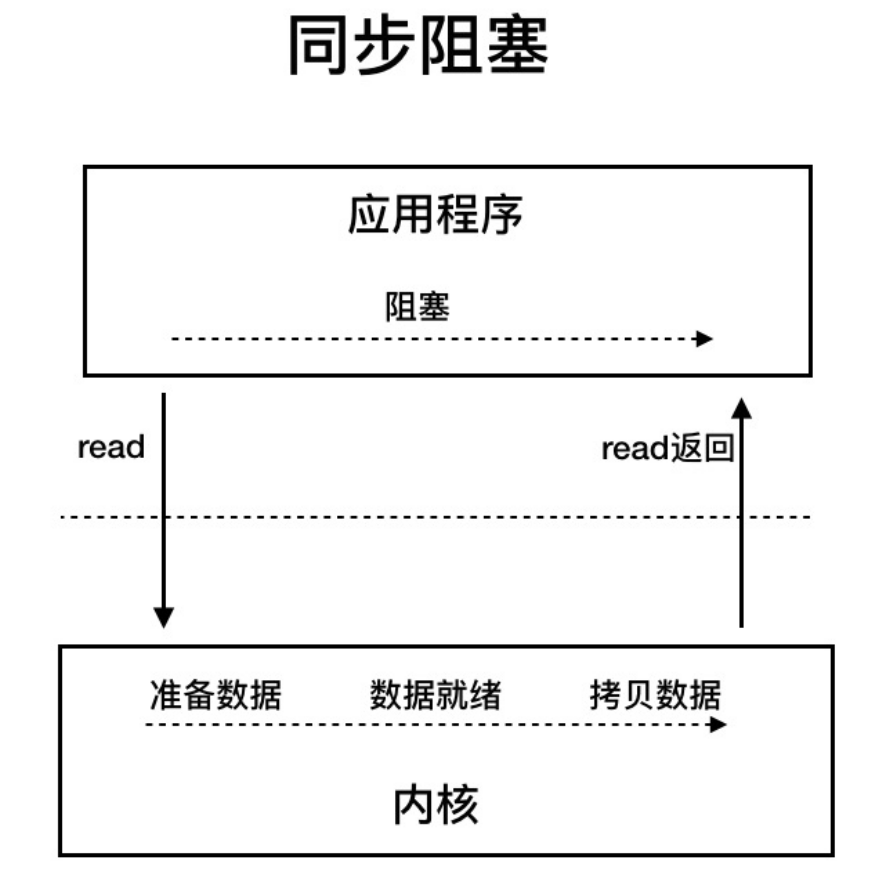
用户线程发起read调用后就阻塞了,让出CPU,内核等待网卡数据到来,把数据从网卡拷贝到内核空间,接着把数据拷贝到用户空间,再把用户线程唤醒
同步非阻塞I/O
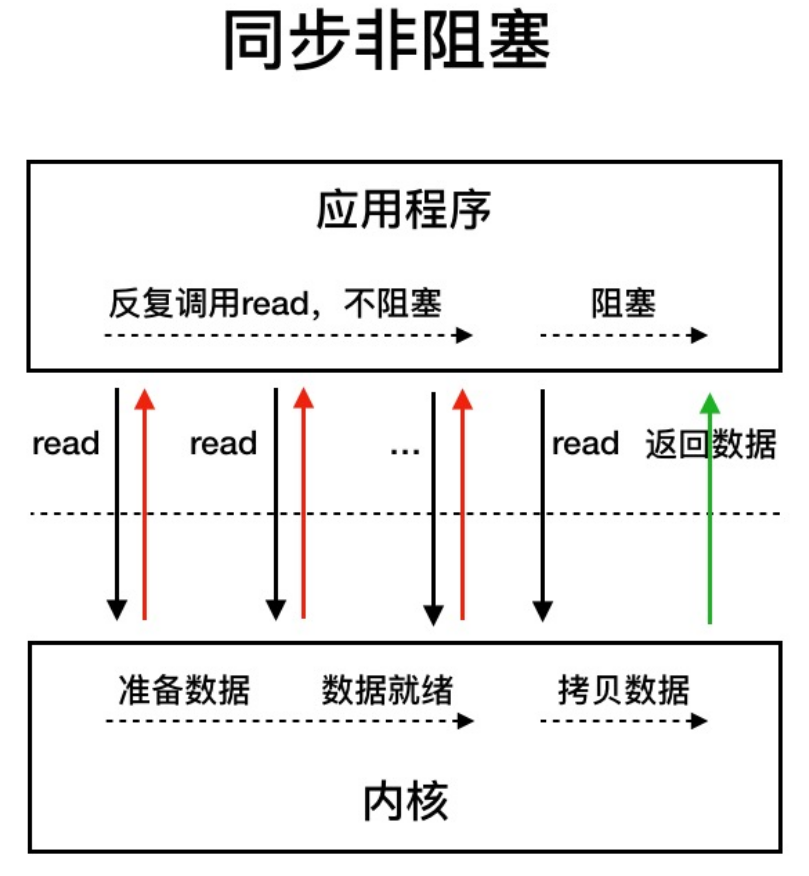
用户线程不断的发起read调用,数据没到内核空间时,每次都发挥失败,直到数据到了内核空间,这一次read调用后,在等待数据从内核空间拷贝到用户空间到这段时间里,线程还是阻塞的,等数据到了用户空间再把线程叫醒
I/O多路复用
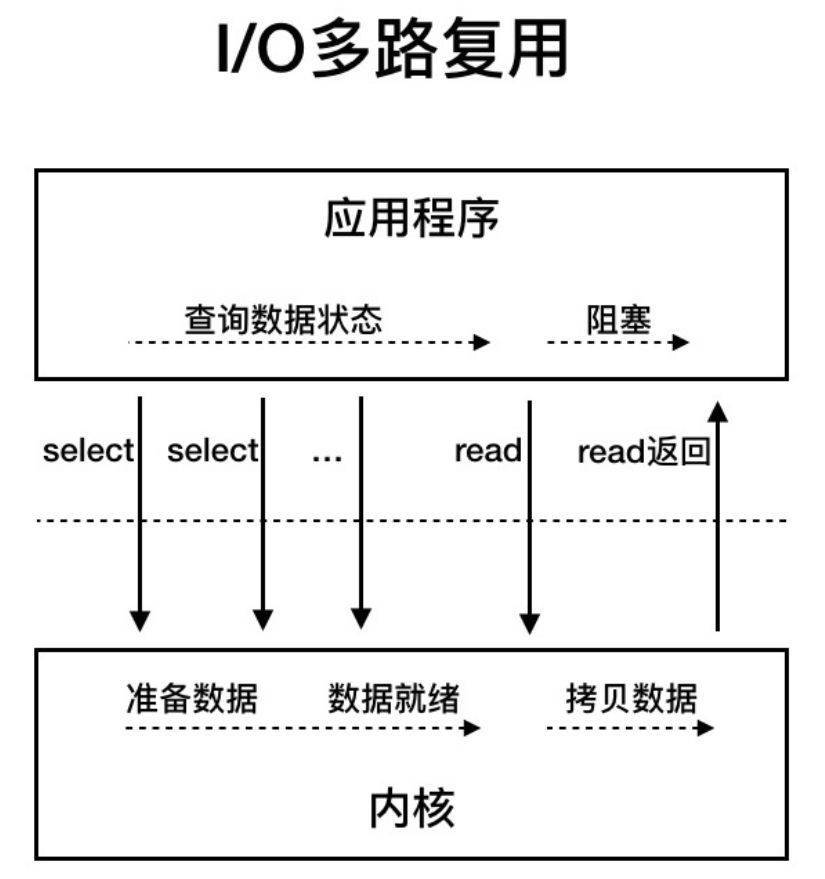
用户线程的读取操作分成两步了,线程先发起select调用,目的是问内核数据准备好了吗?等内核把数据准备好,用户线程再发起read调用,在等待数据从内核空间拷贝到用户空间这段时间里,线程还是阻塞的,和同步非阻塞I/O的不同是,一次select调用可以像内核查多个数据通道(Channel)的状态,所以叫多路复用
异步I/O
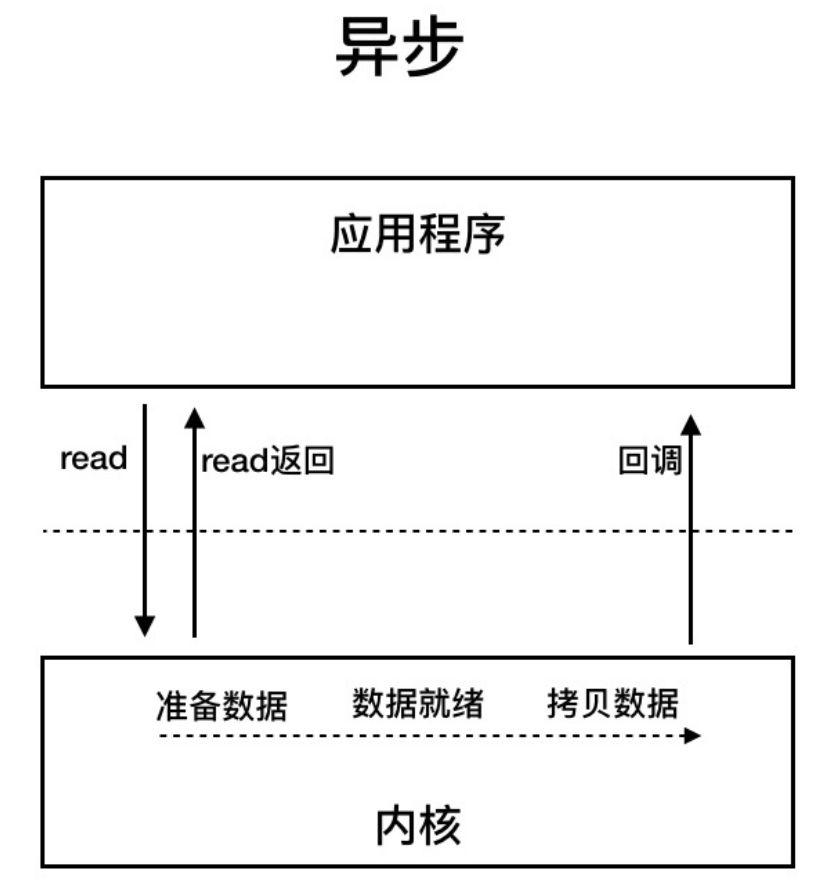
用户线程发起read调用的同时注册一个回调函数,read立即返回,等内核将数据准备好后,再调用指定等回调函数完成处理,这个过程中,用户线程一直没有阻塞
0x02 内核如何阻塞和唤醒进程
从进程谈起
操作系统要运行一个可执行程序,首先要将程序文件加载到内存,然后CPU去读取和执行程序指令,而一个进程就是“一次程序的运行过程”,内核本身是一段程序,系统启动时被首先加载到内存,之后内核调度进程,会给每一个进程创建一个名为task_struct的数据结构,
在有限的物理内存中,需要分给不同的进程,用的是虚拟内存地址,假如32位机器进程的虚拟内存地址空间是4GB,从0x00000000到0xFFFFFFFF,但是这4GB不是真实的物理内存,是进程访问到的某个虚拟地址,如果这个地址还没有对应的物理内存,就会产生缺页中断,分配物理内存,MMU(内存管理单元)会将虚拟地址与物理内存页的映射关系保存在页表中,再次访问这个虚拟地址,就能找到相应的物理内存页
进程的虚拟地址空间
+--------------------------+ 0xFFFFFFFF
| 内核空间 task_struct |
+--------------------------+ 0xC0000000
| 环境变量 |
+--------------------------+
| 栈 |
+--------------------------+
| ... |
+--------------------------+
| 公享库和mmap映射区 |
+--------------------------+
| ... |
+--------------------------+
| 堆 |
+--------------------------+
| 数据区 |
+--------------------------+
| 代码区 |
+--------------------------+ 0x00000000
进程的虚拟地址空间总体分用户空间和内核空间,低地址上3GB属于用户空间,高地址的1GB是内核空间,基于安全考虑,用户程序只能访问用户空间,内核程序可以访问整个进程空间,并且只有内核可以访问各种硬件资源,用户程序只能通过系统调用(内核实现的函数)访问硬件资源
CPU在执行系统调用的过程中会从用户态切换到内核态,CPU在用户态下执行用户程序,使用的是用户空间的栈,访问用户空间的内存,当CPU切换到内核态后,执行内核代码,使用的是内核空间上的栈
用户空间从低到高依次是代码区、数据区、堆、共享库与mmap内存映射区、栈、环境变量,其中堆向高地址增长,栈向低地址增长
mmap内存映射区是Linux提供的内存映射函数mmap,它可将文件内容映射到这个内存区域,用户通过读写这段内存,从而实现对文件的读取和修改,无需通过read/write系统调用来读写文件,省去了用户空间和内核空间之间的数据拷贝,用户程序用到的系统共享库也是通过mmap映射到了这个区域
task_struct结构体本身是分配在内核空间的,它的vm_struct成员变量保存了各内存区域的起始和终止地址,此外task_struct中还保存了进程的其他信息,比如进程号、打开的文件、创建的Socket以及CPU运行上下文等
在Linux中,线程是一个轻量级的进程,轻量级说的是线程只是一个CPU调度单元,因此线程有自己的task_sturct结构体和运行栈区,但是线程的其他资源都是跟父进程共用的,比如虚拟地址空间、打开的文件和Socket等
阻塞和唤醒如何实现
Linux内核将线程当作一个进程进行CPU调度,内核维护了一个可运行的进程队列,所有处于TASK_RUNNING状态的进程都会被放入运行队列中,本质是用双向链表将task_struct链接起来,排队使用CPU时间片,时间片用完重新调度CPU。所谓调度就是在可运行进程列表中选择一个进程,再从CPU列表中选择一个可用的CPU,将进程的上下文恢复到这个CPU的寄存器中,然后执行进程上下文指定的下一条指令
阻塞的本质就是将进程的task_struct移出运行队列,添加到等待队列,并且将进程的状态置为TASK_UNINTERRUPTIBLE或者TASK_INTERRUPTIBLE,重新触发一次CPU调度让出CPU
线程在加入到等待队列的同时向内核注册了一个回调函数,告诉内核我在等待这个Socket上的数据,如果数据到了就唤醒我,这样当网卡接收到数据时,产生硬件中断,内核再通过调用回调函数唤醒进程
唤醒的过程就是将进程的task_struct从等待队列移到运行队列,并且将task_struct的状态置为TASK_RUNNING,这样进程就有机会重新获得CPU时间片,这个过程中,内核还会将数据从内核空间拷贝到用户空间的堆上,当read系统调用返回时,CPU又从内核态切换到用户态,继续执行read调用的下一行代码,并且能从用户空间上的Buffer读到数据了
0x03 HTTP服务器如何使用I/O模型
常见的Python WSGI Server Demo
import socket
import threading
class WSGIServer(object):
def __init__(self, port):
self.tcp_server_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
self.tcp_server_socket.bind(("", port))
self.tcp_server_socket.listen(100)
def run_forever(self):
while True:
client_socket, _ = self.tcp_server_socket.accept()
t = threading.Thread(target=self.service, args=(client_socket))
t.start()
def service(self, socket):
while True:
receive_data = socket.recv(1024)
if receive_data:
socket.send('ok'))
else:
break
socket.close()
def main(port):
wsgi_server = WSGIServer(port)
wsgi_server.run_forever()
if __name__ == '__main__':
main(8080)
同步阻塞I/O模型
我们上面的这个Demo就是Python的同步阻塞I/O模型
每次收到客户端连接后,开启一个线程,socket.recv阻塞,等待网络数据的到来,服务器之所以能够处理多个client的请求,是通过线程来处理的,如果线程的主要任务只是很少用到CPU的返回“OK”,这里不断开启销毁线程(线程池可以减缓但不是解决主要矛盾的方式),线程数量叠加和线程等待对追求性能的程序非常浪费资源
同步非阻塞I/O模型
我们将server.setblocking(False)并改动一下service函数
def service(self, socket):
while True:
try:
receive_data = socket.recv(1024)
if receive_data:
socket.send('ok'))
else:
break
except BlockingIOError:
time.sleep(2)
socket.close()
我们不断try/except来使用socket.recv,在捕获到错误后我们可以sleep让出资源,这样就可以减少一些计算资源的浪费,当然这样每隔几秒轮询肯定不实时,而且大量socket.recv大幅提高CPU占用,这样代码也很不好
I/O多路复用模型
上面的代码我们想一想改进,我们用一个线程复用多个socket,用一个数组来保存socket,每次单个线程循环的时候不只得到一个socket的结果,而是数组中所有socket存在有数据时处理那个socket,就不用多开很多个线程了,这也是I/O多路复用的思路
Python的select模块就是处理这个的,同样,我们将server.setblocking(False),然后修改run_forever函数
def run_forever(self):
sockets = [self.tcp_server_socket,]
r_list, _, _ = select.select(sockets, [], [])
for socket in r_list:
if obj == self.tcp_server_socket:
conn, _ = obj.accept()
sockets.append(conn)
else:
t = threading.Thread(target=self.service, args=(client_socket))
t.start()
相比其他模型,I/O多路复用模型可以只用单线程(进程)执行,占用资源少,不消耗太多 CPU, 就可以同时为多客户端提供服务
异步I/O模型
这个Python的相关接口实现我不是很熟悉,平时只写过asyncio HTTP客户端异步请求的代码,没接触就不写Demo了,但是知道异步I/O是在read后,内核拷贝数据到用户进程,也就是read后就可以做其他事情了,所以一般来说,异步I/O模型肯定比上面的模型效率要高,因为I/O复用模型使用select后,recv的过程还是要阻塞
0x04 select/pool/epool
其实这三者都是I/O复用模型的内核函数接口
以前听说的C10k(并发1w)的问题,就是互联网早期,一个TCP连接分配一个进程(线程),也就是用同步阻塞、同步非阻塞模型处理请求,后来用户增加,一台机器无法创建那么多的进程,为了解决这个问题,出现用同一个进程/线程来处理若干连接的思路,就是I/O多路复用模型,解决方法就是从select/pool升级到epool
select:每个连接对应一个描述符(socket),循环处理各个连接,先查下它的状态,ready了就进行处理,不ready就不进行处理
缺点很多
- 单个进程能够监视的文件描述符的数量存在最大限制
- 对socket进行扫描时是线性扫描,即采用轮询的方法,效率较低
- 需要维护一个用来存放很大的数据结构,这样会使得用户空间和内核空间在传递该结构时复制开销大
poll:本质上和select没有区别,但是由于它是基于链表来存储的,没有最大连接数的限制
缺点是:
- 大量的的数组被整体复制于用户态和内核地址空间之间,而不管这样的复制是不是有意义
- poll的特点是「水平触发(只要有数据可以读,不管怎样都会通知)」,如果报告后没有被处理,那么下次poll时会再次报告它
epoll:它使用一个文件描述符管理多个描述符,将用户关系的文件描述符的事件存放到内核的一个事件表中,这样在用户空间和内核空间的copy只需一次,epoll支持水平触发和边缘触发,最大的特点在于「边缘触发」,它只告诉进程哪些刚刚变为就绪态,并且只会通知一次。使用epoll的优点很多:
- 没有最大并发连接的限制,能打开的fd的上限远大于1024(1G的内存上能监听约10万个端口)
- 效率提升,不是轮询的方式,不会随着fd数目的增加效率下降
- 内存拷贝,利用mmap()文件映射内存加速与内核空间的消息传递;即epoll使用mmap减少复制开销
epoll技术的编程模型就是异步非阻塞回调,也可以叫做Reactor、事件驱动、事件轮循(EventLoop)、libevent、Tornado、Node.js这些就是epoll时代的产物,这些我都不太清楚,但是牛逼就完事了
我只知道EventLoop,简单来说就是程序中设置两个线程:一个负责程序本身的运行,称为“主线程”,一个负责主线程与其他线程(主要是I/O操作)的通信,称为“Event Loop”线程,运行时遇到I/O,主线程就让Event Loop去完成,然后往后运行,EventLoop等I/O完成后,把结果返回主线程,主线程调用回调函数,完成任务
可是epoll 自身是基于IO多路复用模式的同步IO模型,可实现基于事件驱动的异步非阻塞的进程模型,不要把进程模型的异步分阻塞看成异步IO
时代在发展,如今已经不讨论C10k问题,而是10M、100M这样的挑战
0x05 协程
我们在I/O模型等演进过程中,根本等思路是要高效去阻塞,让CPU干核心的任务,C10K解决后,对与10M有两个不足
1.进程/线程作为处理单元太厚重 2.系统调度的代价太高,大量线程/进程处于ready状态时,系统需要不断切换,上下文切换代价太大
于是协程出现了,作为一种更轻量级的进程/线程处理单元
协程在实现上都是试图用一组少量的线程来实现多个任务,一旦某个任务阻塞,则可能用同一线程继续运行其他任务,避免大量上下文的切换
每个协程所独占的系统资源往往只有栈部分,而且,各个协程之间的切换,往往是用户通过代码来显式指定的(跟各种 callback 类似),不需要内核参与,可以很方便的实现异步
协程本质上也是异步非阻塞技术,它是将事件回调进行了包装,让程序员看不到里面的事件循环
简单来说,进程/线程是操作系统充当了EventLoop调度,协程是自己用epool进行调度

